
Examples that will be covered on this article
1. Real-time monitoring meets real-time analytics
2. Security and anomaly detection
3. Online data integration
Hope you enjoy it!
Requirements
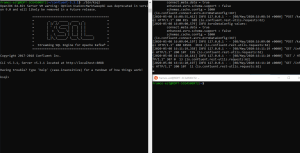
To demonstrate these use cases, we need three terminals open. The one on the left contains the KSQL command line to make the queries and the one in upper right corner is running the KSQL server. Finally, the bottom right terminal to produce events to our test topics.
#1 Real-time monitoring meets real-time analytics
With KSQL you can monitor data as it comes into a chosen Kafka topic. Furthermore, you can also analyze if the data coming in that topic has a normal behavior or not. This can be very helpful because it alerts in real-time when that behavior changes.
For example:
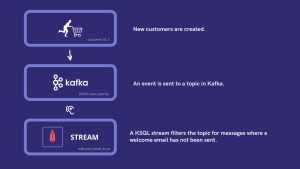
Suppose whenever a customer creates an account, an event is sent to a topic. This event contains the customer’s Id, first and last name, email, its plan, and a field called welcome_email. This last field tracks whether a customer has received a welcome email upon creating his account. In this use case we will create a stream and a table that will allow us to monitor in real time every client that did not receive that email. Adding to this we will also count the total amount of those clients.
Step 1: In the KSQL command line we are now printing everything that comes into the topic.
print 'DEMO.newcustomer'
Step 2: Here we have the a text file we called new_customers.txt with some Json content to produce several events to a Kafka topic called “DEMO.newcustomer”.
{"customer": {"customer_id": "0001","first_name": "Lars","last_name": "Treagus","email": "ltreagus0@timesonline.co.uk"},"welcome_email": "yes", "plan": "platinum"}{"customer": {"customer_id": "0002","first_name": "Joe","last_name": "Bon","email": "jooebon@timesonline.co.uk"},"welcome_email": "no", "plan": "gold"}{"customer": {"customer_id": "0003","first_name": "Peter","last_name": "Rolland","email": "peteroll@timesonline.co.uk"},"welcome_email": "no", "plan": "gold"}{"customer": {"customer_id": "0004","first_name": "Julia","last_name": "Pegg","email": "jupegg@timesonline.co.uk"},"welcome_email": "yes", "plan": "none"}{"customer": {"customer_id": "0005","first_name": "Mark","last_name": "Ash","email": "markash0@timesonline.co.uk"},"welcome_email": "no", "plan": "silver"}{"customer": {"customer_id": "0006","first_name": "Rose","last_name": "Amber","email": "ramber@timesonline.co.uk"},"welcome_email": "no", "plan": "platinum"}{"customer": {"customer_id": "0007","first_name": "Jack","last_name": "Fields","email": "jfields@timesonline.co.uk"},"welcome_email": "yes", "plan": "silver"}
Step 3: This screenshot shows us the producer that sends those events to the topic.
./bin/kafka-console-producer --broker-list k8s.myserver.red:90000 –topic DEMO.newcustomer < new_customers.txt
Step 4: All the events were produced to the topic, KSQL also recognizes its format. Data is coming into the topic, but is there a way to format this data into a more user-friendly view?
print 'DEMO.newcustomer'
Step 5: To start processing the data coming on that topic we first must create a stream (new_customer_stream). This stream is going to subscribe to a topic. Additionally, we will have to map the fields we want to receive and define their datatypes. The JSON events coming in also have a nested field customer (that we attributed the datatype STRUCT). Because of this we will have to create a new stream to access its sub fields.
CREATE STREAM new_customer_stream(customer STRUCT<customer_id VARCHAR,first_name VARCHAR,last_name VARCHAR,email VARCHAR>,welcome_email VARCHAR,plan VARCHAR)WITH (KAFKA_TOPIC='DEMO.newcustomer', VALUE_FORMAT='JSON');

Step 6: Above, we created a new stream to access the first name, last name and email in the customer field. With this, when we select from this stream, it shows us each field in an individual column.
CREATE STREAM new_customer_sorted AS SELECT customer->customer_id AS CUSTOMER_ID,customer->first_name AS FIRST_NAME,customer->last_name AS LAST_NAME,customer->email AS EMAIL,welcome_email,planFROM new_customer_stream;After running the previous piece of code, you will have the same output as Figure 7.
Step 7: Here, we produce two new events to the topic.
./bin/kafka-console-producer --broker-list k8s.myserver.red:90000 –topic DEMO.newcustomer
{"customer": {"customer_id": "0010","first_name": "Raul","last_name": "Sanchez","email": "rsanchez@timesonline.co.uk"},"welcome_email": "yes", "plan": "platinum"}{"customer": {"customer_id": "0011","first_name": "Julia","last_name": "Knight","email": "juliakn@timesonline.co.uk"},"welcome_email": "no", "plan": "platinum"}
Step 8: The next step is selecting all the data coming in the new_customer_sorted stream and get this more abstract view of the data coming in.
SELECT * FROM NEW_CUSTOMER_SORTED;

Step 9: After selecting our data, we can now see it in a more organized way. However, we want to process that data and monitor some information. For that we are going to create a stream (welcome_email_error) that is going to select only the records that have the field ‘welcome_email’ set to “no”. Now, every time a client doesn’t receive a welcome email we get an alert in real time.
CREATE STREAM welcome_email_error AS SELECT * FROM NEW_CUSTOMER_SORTED WHERE welcome_email = 'no';After running the previous piece of code, you will have the same output as Figure 7.
Step 10: Next, we produce two events, where this field is different.
./bin/kafka-console-producer --broker-list k8s.myserver.red:90000 –topic DEMO.newcustomer
{"customer": {"customer_id": "0012","first_name": "Lizza","last_name": "Banks","email": "lizzabanks@timesonline.co.uk"},"welcome_email": "yes", "plan": "platinum"}{"customer": {"customer_id": "0013","first_name": "Leonel","last_name": "Simmons","email": "leosimmnons@timesonline.co.uk"},"welcome_email": "no", "plan": "platinum"}
Step 11: As expected, only the event with the welcome field set to “no” has come into the stream.
SELECT * FROM WELCOME_EMAIL_ERROR

#2 Security and anomaly detection
Security use cases often look a lot like monitoring and analytics. Rather than monitoring application behavior or business behavior we are looking for patterns of fraud, abuse, or other bad behavior. KSQL gives a simple, sophisticated, and real-time way of defining these patterns and querying real-time streams.
In this case:
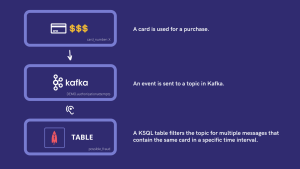
Step 1: Here we have the a text file we called card_transactions.txt with some Json content to produce several events to a Kafka topic called “DEMO.authorizationattempts”.
For this use case, every time there is a card transaction, an event is sent to a topic. KSQL is going to look for any card that is being used multiple times in a very small interval where these actions wouldn’t be humanly possible. Monitor this data with this pattern allows us to detect any suspicion of card fraud.
{"card": {"card_number": "111111111111","card_name": "Mike Jay","validation_date": "01/22"},"transaction_status": "accepted", "debit_amount": "97.5€"}{"card": {"card_number": "222222222222","card_name": "Mike Paul","validation_date": "01/22"},"transaction_status": " accepted ", "debit_amount": "20.5€"}{"card": {"card_number": "333333333333","card_name": "Ron Jackson","validation_date": "03/22"},"transaction_status": "accepted", "debit_amount": "17€"}{"card": {"card_number": "444444444444","card_name": "Barbara John","validation_date": "03/21"},"transaction_status": "declined", "debit_amount": "530€"}{"card": {"card_number": "55555555555","card_name": "Ruth Banks","validation_date": "10/20"},"transaction_status": " accepted ", "debit_amount": "120€"}{"card": {"card_number": "66666666666","card_name": "Francis Joe","validation_date": "09/22"},"transaction_status": "declined", "debit_amount": "520€"}{"card": {"card_number": "777777777777","card_name": "Mike Jacobs","validation_date": "06/22"},"transaction_status": " accepted ", "debit_amount": "500€"}{"card": {"card_number": "88888888888","card_name": "Julia Jacobs","validation_date": "10/23"},"transaction_status": "declined", "debit_amount": "5€"}
Step 2: Like the use case before we must map everything, choose which topic we are going to listen to and define the format of the data coming in.
CREATE STREAM authorization_attempts(card STRUCT<card_number VARCHAR,card_name VARCHAR,validation_date VARCHAR>,transaction_status VARCHAR,debit_amount VARCHAR)WITH (KAFKA_TOPIC='DEMO.authorizationattempts', VALUE_FORMAT='JSON');
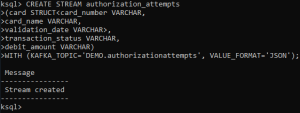
Step 3: Because of the nested JSON we discussed before, we are creating another stream to access those nested fields.
CREATE STREAM authorization_sorted AS SELECT card->card_number AS CARD_NUMBER,card->card_name AS CARD_NAME,card->validation_date AS VALIDATION_DATE,transaction_status,debit_amountFROM AUTHORIZATION_ATTEMPTS;
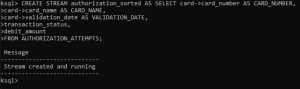
Step 4: After creating the stream with every field sorted out, we now produce the events to the topic to test if the events are captured by the stream.
./bin/kafka-console-producer --broker-list k8s.myserver.red:90000 –topic DEMO.authorizationattempts < card_transactions.txt
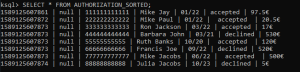
Step 5: The stream captures all the events.
SELECT * FROM AUTHORIZATION_SORTED
Step 6: In here, we are creating a table to check for fraudulent behavior in a time interval of 5 seconds. This table will also count how many times a specific card is used in that time span.
CREATE TABLE possible_fraud ASSELECT card_number,card_name, COUNT(*) AS ATTEMPTSFROM authorization_sorted WINDOW TUMBLING (SIZE 5 SECONDS) GROUP BY card_number, card_name HAVING COUNT(*)>3;

Step 7: Above, we produce to a topic 6 events with the same card number and name in less than 5 seconds.
./bin/kafka-console-producer --broker-list k8s.myserver.red:90000 –topic DEMO.authorizationattempts {"card": {"card_number": "88888888888","card_name": "Julia Jacobs","validation_date": "10/23"},"transaction_status": "declined", "debit_amount": "5€"}{"card": {"card_number": "88888888888","card_name": "Julia Jacobs","validation_date": "10/23"},"transaction_status": "declined", "debit_amount": "5€"}{"card": {"card_number": "88888888888","card_name": "Julia Jacobs","validation_date": "10/23"},"transaction_status": "declined", "debit_amount": "5€"}{"card": {"card_number": "88888888888","card_name": "Julia Jacobs","validation_date": "10/23"},"transaction_status": "declined", "debit_amount": "5€"}{"card": {"card_number": "88888888888","card_name": "Julia Jacobs","validation_date": "10/23"},"transaction_status": "declined", "debit_amount": "5€"}{"card": {"card_number": "88888888888","card_name": "Julia Jacobs","validation_date": "10/23"},"transaction_status": "declined", "debit_amount": "5€"}
Step 8: The table immediately updates with the event and calculates how many times that card was used in 5 seconds. It also shows its details, so that security can act on these suspicious actions in real time.
SELECT * FROM POSSIBLE_FRAUD;

#3 Online data integration
Much of the data processing done in a lot of companies falls in the domain of data enrichment. This means taking data coming out of several databases, transform it, join it together and performing many other operations. For a long time, ETL (Extract, Transform, and Load) for data integration was performed as periodic batch jobs. To exemplify, dump the raw data in real time, and then transform it every few hours to enable efficient queries. In many use cases, this delay is unacceptable.
For this use case:
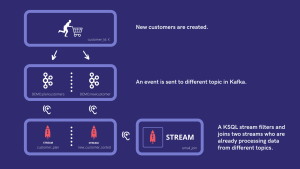
We already have one stream listening to a topic. We will create a new stream that will listen to two streams that listen themselves to different topics. This can show how KSQL can really improve a company in the domain of data enrichment by joining data coming from different sources and process it in real time.
In this use case when a new customer creates an account, it also sends a different event to a different topic. However, that topic relates with the plan management of every customer.
We already have one stream connected to another topic related to customer creation we created on the monitoring use case. So, the plan here is to join these two streams together with the information we require. By doing this we are creating a new stream from existing ones without the need to remap our events and deal with nested fields for example.
Step 1: The text file with the events to send to the topic ‘DEMO.plancustomers’.
{"customer_id": "00001","plan": "silver","last_debit" :"3" ,"trial": "no"}{"customer_id": "00002","plan": "gold","last_debit" :"5" ,"trial": "no"}{"customer_id": "00003","plan": "platinum","last_debit" :"0" ,"trial": "yes"}{"customer_id": "00004","plan": "gold","last_debit" :"5" ,"trial": "no"}{"customer_id": "00005","plan": "platinum","last_debit" :"0" ,"trial": "yes"}
Step 2: Creating the stream, mapping, the usual (notice that we are not dealing with nested JSON anymore so creating only one stream is enough).
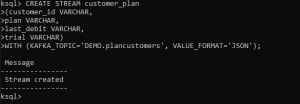
CREATE STREAM customer_plan(customer_id VARCHAR,plan VARCHAR,last_debit VARCHAR,trial VARCHAR)WITH (KAFKA_TOPIC='DEMO.plancustomers', VALUE_FORMAT='JSON');
Step 3: Using our producer to send the events to the topic.
./bin/kafka-console-producer --broker-list k8sdev.siege.red:30100 --
Step 4: Checking if the stream is working correctly.
SELECT * FROM CUSTOMER_PLAN

Step 5: Our new stream is working as expected. Now we’re creating a new stream to join the ‘customer_plan’ stream we just created, with the existing stream created before ‘new_customer_sorted’. We also set the time interval of 2 hours.
CREATE STREAM email_join AS SELECT u.customer_id, u.trial, c.email FROM new_customer_sorted c LEFT JOIN customer_plan u WITHIN 2 HOURS ON c.customer_id = u.customer_id WHERE c.plan= 'platinum';

Step 6: Producing an event to the ‘DEMO.plancustomers’ topic.
./bin/kafka-console-producer --broker-list k8sdev.siege.red:30100 –topic DEMO.plancustomer{"customer_id": "00014","plan": "platinum","last_debit" :"0" ,"trial": "yes"}{"customer_id": "00015","plan": "gold","last_debit" :"5" ,"trial": "no"}{"customer_id": "00016","plan": "silver","last_debit" :"3" ,"trial": "no"}{"customer_id": "00017","plan": "platinum","last_debit" :"0" ,"trial": "yes"}
Step 7: There is still no data coming into this stream because no event was produced to the other topic with the same customer ID.
SELECT * FROM EMAIL_JOIN

Step 8: Now we produce to the ‘DEMO.newcustomer’ an event with the same customer ID.
./bin/kafka-console-producer --broker-list k8sdev.siege.red:30100 --topic DEMO.newcustomer {"customer": {"customer_id": "00014","first_name": "Mark","last_name": "Brown","email": "markbrown@timesonline.co.uk"},"welcome_email": "yes", "plan": "platinum"}{"customer": {"customer_id": "00015","first_name": "Joanne","last_name": "Dickson","email": "joanned@timesonline.co.uk"},"welcome_email": "yes", "plan": "gold"}{"customer": {"customer_id": "00016","first_name": "Josh","last_name": "Walter","email": "joshwalter@timesonline.co.uk"},"welcome_email": "yes", "plan": "silver"}{"customer": {"customer_id": "00017","first_name": "Philip","last_name": "Sawyer","email": "psawyer@timesonline.co.uk"},"welcome_email": "yes", "plan": "platinum"}
Step 9: As we can see the stream picks up on the information on the two streams of two different topics and joined their information.
SELECT * FROM EMAIL_JOIN

That’s it
If you are still reading this, you’ve made it till the end.
I hope these examples have been useful and don’t forget, if you would like to explore more, please go to KSQL page to further expand your knowledge on this powerful tool.