Our first services – that resemble our current technical solution for microservices in the public cloud – were versioned in SVN. For these, we used the trunk-based development approach, which suited our needs very well; we were working in a 1 to 1 scenario: one project, one developer, with features that were specified, developed and deployed quickly to Production. We shifted from a complex and manual delivery process to a quicker and more reliable one with trunk-based development.
When moving to Git, using Gitlab, it was natural for us to follow a similar working method, i.e. implanting a trunk-based way of versioning our code. The main difference was: now our trunk was the main branch. After the first proposition of this branching model for Git, the engineering team raised concerns about traceability of commits/requests, readability of the versioning history in Git, and applicability in complex projects. By “complex” we meant to discuss: how we would handle several software engineers developing features in the same project?
Following the team’s feedback, we analyzed the options available and our use cases, and we then defined two main branching strategies: Trunk-based with Git and Gitflow. We also shared our proposed models with the Architecture & Tech team and the DevOps team since this topic is relevant in the Infra as a Code era. The following paragraphs explain these models and the underlying motivation for each one.
Trunk-based with Git, a short time lived feature branch
The word “trunk” in a branching model for Git can cause some distress to the more conservative since it is tightly coupled with the SVN way of working. Nevertheless, we have decided to keep this keyword mainly because of the positive aspects of this approach in our previous stack: the possibility of moving quickly to Production after a commit. We want to go faster without compromising the quality of what we are delivering.
This strategy is the one that we want our developers to adopt. We assume that this model targets 99% of our current project stack — microservices, Kafka producers and consumers — focusing on event-driven, decoupled, and “micro” architectures. Therefore, the cycle times are fast, taking a few hours or even minutes, and we keep the 1:1 ratio.
If we get into a situation where a microservice has more than two developers working on different features, we should take a step back and ask: “Ok, maybe this component is too complex, and maybe we have addressed it the wrong way? Have we created a mini monolith without realising it? How can we improve our architecture design processes to avoid this in the future?”.
The existence of feature branches also aligns with our systematic search for improved quality since branches promote controlled pull requests, code review, and, to some extent, a knowledge transfer between members of the team. We want to encourage sustainable mid-term quality over short-term quality. Figure 1 depicts this model, where we can see the main branch (in green) and the feature branches (in blue) that must be short-lived.
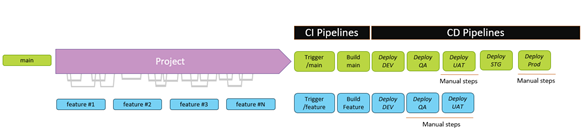
As you may notice in Figure 1, we deploy in several non-production environments, each with a different purpose in our delivery process (also an interesting topic to discuss in a dedicated article). After the deployment, we trigger test campaigns that validate our developments in each environment, including Production. In the first version of our pipeline configuration, a feature branch could only deploy its artifact in the DEV environment; however, one team mentioned the need to deploy a feature till UAT before integrating the feature in the main. Once again, this requirement was context-related, i.e., the team could only test this feature properly in UAT. The components that interacted with it were not truly “testable” in DEV or QA, and the team needed to push the project to UAT to perform even basic functional validations. With the first approach, we faced the risk of integrating modifications in the main branch without testing them properly in the feature branch, and that’s why now our feature branches allow us to deploy till UAT.
When a feature is integrated into the main branch, the deployment flow re-starts in the DEV environment. Considering our experience, we thought that this was the best approach to ensure that everyone had visibility of the last developments done. If we skipped the deployment in DEV, someone who called one API in DEV would not execute the latest code integrated into that environment. As for hotfixes, these are treated as any other branches.
Gitflow
Gitflow is a well-known workflow, one of the first deployed in the community, identified as one of the de-facto patterns for branching models. Nevertheless, this is not always the best approach since this model adds complexity and violates the “short-lived” branches rule as you can see in Figure 2. Despite that, we included this as a viable strategy to use in certain conditions.
The Gitflow is the “assess” strategy because it represents the exception. If we need to choose this model, we are developing components that are far from being true microservices. Applications that fit this model are the ones that are mainly tightly coupled and “macro” in size. The applications’ cycle and waiting times are long and can take days or weeks; these involve various developers on the same code base or linked components.
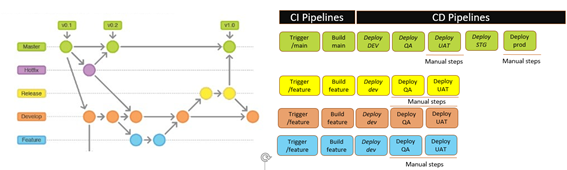
As you can see in Figure 2, we have kept the same principle; any branch other than the main can deploy till UAT if the team has that specific need. When the feature is integrated into the main, the pipeline will also go through all stages (deploy and testing).
Lessons learned and Roadmap
We can ask ourselves about the need to define these strategies internally when there are enough workflows shared by the community. For us, this need is related to each team’s context and to the company’s trajectory. Legacy impacts our ways of working, either by the methodologies that sometimes are not adapted to a new reality or by the technology itself that poses some limitations.
For example, a startup may not have the same challenges as an older company. It may be easy to start a Git repository in a startup, implementing a flow that seems to fit et voilà! But the challenges we observed may arrive sooner or later when the size of the team increases or when the business requires quick product improvements.
An important lesson learned with this definition of our valid branching models is that we need to identify our use cases very well. We need to understand the needs of each team (e.g., need to deploy a feature branch till UAT). Also, it’s essential to communicate the process and keep a close follow-up with the teams to identify improvements that can lead to efficient operations and better products.
As part of our Roadmap, we expect to implement monitoring to ensure the optimization of our pipelines: execution times and the executed workflow itself. Additionally, we intend to scale these branching strategies to other teams inside the company, such as the DATA team.

