
Apache Kafka is a successful example of an open-source product adopted at scale. A significant part of Fortune 100 companies relies on the technology to capture the value of data in motion through distributed streaming architecture.
Over time, its usage has been expanding to a more significant part of the ecosystem for various use-cases. It even becomes a de-facto standard for ingesting a large set of data without worrying that much. Even if Kafka is a reliable platform, the technology does not work only by itself.
The administration, usage, and access to the data become critical once Kafka is used to important business data. A user interface becomes a requirement in such a context. This article shares how we decided to address this question with an open-source approach.
Before digging into the implementation details, we need to start with why, our motivations.
Why using an interface with Kafka?
When starting to use Kafka, we deploy the broker, implement our first producer and consumer. We are proud of the results once we resolved all the integration issues such as access management, network, and deployment. When we work as a single developer, we can do a simple query, and looking at the Kafka topic; we do not face specific problems.
Our next step is to use Kafka for a real use-case in our company. A good practice is to dedicate specific environments we can use through our CI/CD toolchain. To achieve that, we create dedicated brokers per environment, increasing the number of producers and consumers in parallel. The increasing volume of data started to gain more interest within the organization.
This is where we need a simple way for the team to answer their use-cases on Kafka.
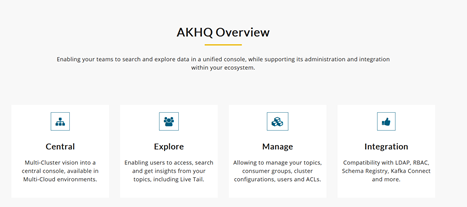
Multiple developers will want to access the data in their topics, limiting the use of a specific command-line tool for ease of usage. The non-technical users will have similar requirements of visualization with simplicity. They want the data without being limited by the implementation details. Additionally, the people responsible for operating the platform require specific administration tasks for the broker and topics.
It seems like a common requirement for a so broadly deployed solution such as Apache Kafka. A solution must exist already, right?
We decided to contribute to open source
We started to work on Kafka around 2018 at La Redoute. At that time, the trend around technology was already expanding inside the ecosystem. Confluent was also present while a set of open-source projects were emerging.
In our context, we decided to rely on the open-source version of Apache Kafka, even if relying on managed services. That means the administration console of Confluent was not something available to use. Therefore, we had two options: build our custom solution or select a product we could contribute.
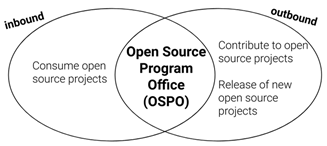
Our engineering stack is already composed of open-source products for years, like the first version of Jenkins, ELK, among others. Complementarily, we did not have a dedicated resource like in an Open-Source Program Office (OSPO) model. Contributing to an existing open-source project was the alternative we then choose.
After a set of assessments, we retained akhq.io, formerly KafkaHQ.
Our contribution consisted of a distributed OSPO
We approached the project leader, Ludovic Dehon, who by coincidence, was based in France near our headquarters. Interestingly, his motivations were similar to ours: bring an open-source interface for Kafka. He was also deploying Kafka for enterprise use-cases.
Concretely, our collaboration relied upon basic yet structured project management. We dedicated a specific workload of internal and external software engineers with our partner Polarising. We organized a kick-off to align the product vision and roadmap. Afterward, the collaboration was happening on GitHub, syncing on Slack, with a bi-weekly sprint review-type meeting.

Our first contributions focused on fixing simple bugs to understand the codebase better and establish collaboration. We then tackled more structuring features like the ACL, a new interface, or multiple topics data move. Today the solution provides the main features to interact with Kafka on the cluster, topics, nodes, consumers, producers. The integration with the Schema registry is also available.
The particularity of a public product is the interactions with its users, in our case, the community.
How did the collaboration happen with the community?
We focused on building a community of users around the solution to validate the value and usability in various contexts. The best marketing was to have happy users using the product and feedback for improvements, then using the network effect. Ludovic also uses Twitter to gain a set of followers.
In the day-to-day project, we relied on GitHub as being a standard open-source project. The issues were used as Q&A and ticketing tools with the various tags happening asynchronously. We did not invest, especially in meetups or other sorts of sharing. We share it once in the Kafka user group we animate in Portugal, with the video replay available.
The communities on GitHub have grown up to 2000 stars of the project on GitHub, and more importantly, more than 85 contributors. The activity, usage, and evolution of an open-source project is one key indicator to have in mind. One strength of open source for smaller projects is to share the maintenance, limiting the organizational risk of doing it alone.
The product is now stable for production usage, with its official website.
Akhq.io, one viable alternative as a Kafka User Interface
We use akhq.io for our Apache Kafka deployments, supporting mainly the engineering teams in their various activities. Our contribution to the open-source product is now limited and remains led by Ludovic Dehon.
We are happy to have contributed to this open-source journey in a distributed model. We see that we do not necessarily need considerable resources to co-create solutions in the ecosystem. The cross-enterprise collaboration was very beneficial to build a richer product.
Alternatives exist and can be considered; the goal was to build a valuable solution for interacting with Kafka. We saw the power of collaboration leveraging technology and platform such as GitHub is powerful. A good step for a product being open source as its roots, supported by companies.
What’s next? Continue contributions and, hopefully, co-create more products in the ecosystem.
Official website https://akhq.io/
GitHub project, akhq.io: https://github.com/tchiotludo/akhq
Special mention to Paulo Marques, lead architect and developer https://www.linkedin.com/in/paulo-m-b794923/
Meetup video presentation, AKUG.PT: https://www.youtube.com/watch?v=Lns5PlCIKAQ
