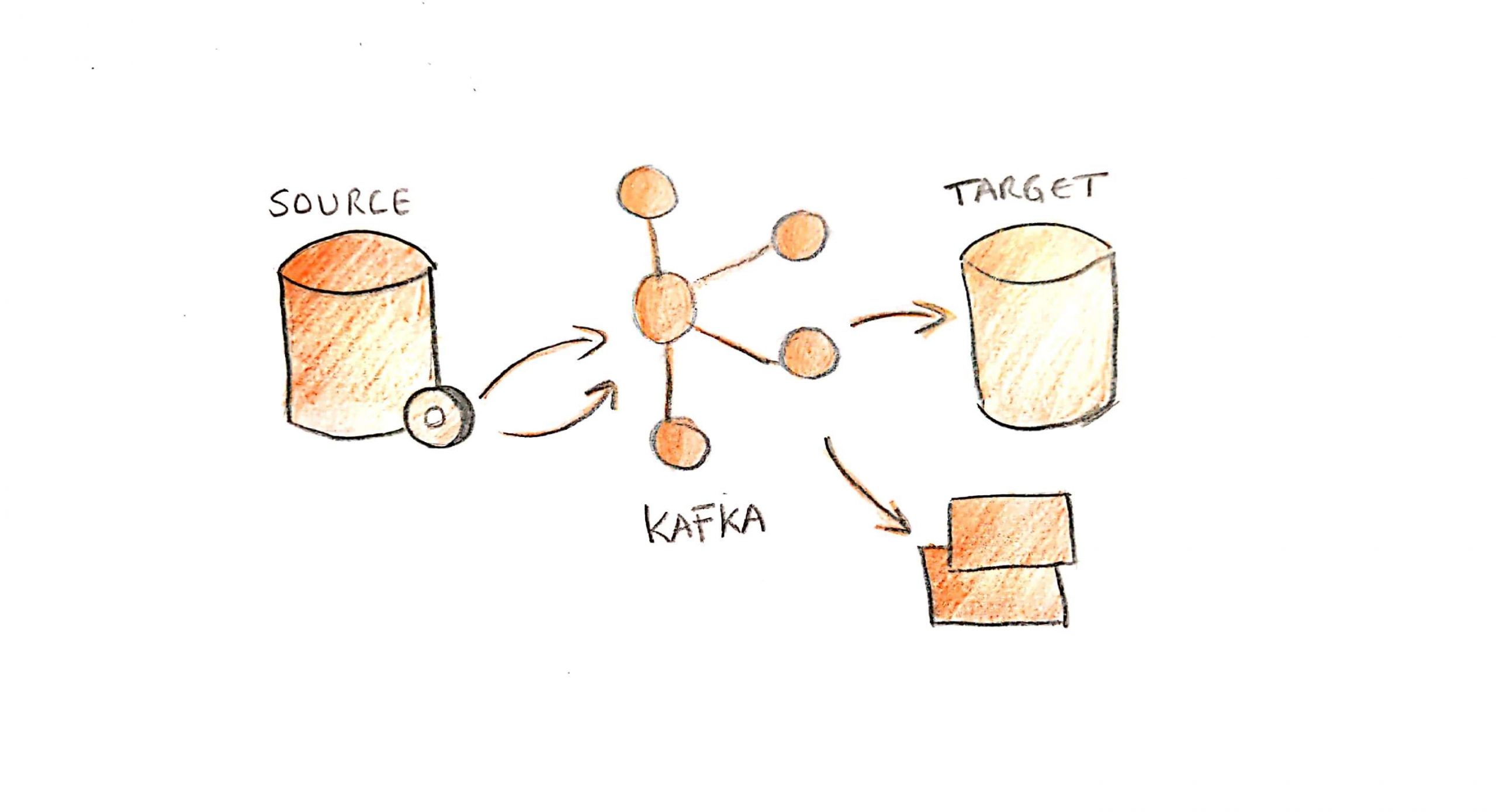
Kafka Connect allowing Change Data Capture
Kafka connect is a core component of Apache Kafka that enables streaming integration both in and out of Kafka. It provides scalable and resilient integration between Kafka and other systems such as databases.
Kafka Connect provides a variety of connectors to allow the capturing of CDC events and stream them to Kafka.
CDC are the initials of Change Data Capture and we can define it as a process that monitors and captures the changes on a data source level, creates a stream of those changes and make them available as events, allowing the consumers react to those changes in near real time. CDC uses the database transaction log (no direct access to the database tables) to extract at very low latency and low impact the events that are occurring on the database.

The use case: partial data replication in near real-time between two databases
Implementing part of the system oriented to micro-services, leads us to a particular use-case: how to decouple two systems and prevent them from accessing a single database just to retrieve configuration data.
The main goals were to avoid system dependencies (solution A represented below), improve operations and maintainability, design high system availability and have real-time data, without reimplementing or replicating the existing and complex ETL (Extract-Transform-Load) processes that feeds the first system.
The chosen solution for our use case was a Kafka CDC implementation, plugging a Kafka Connect connector to the initial database, replicating the data to Kafka and sending it to the target database (represented below as solution B).
In our use case we did not want to have a full replica of the initial database, but just to replicate the data that can be consumed in the future by several systems.

Components needed for the implemented architecture
To implement Kafka CDC oriented to PostgreSQL database and to have the events that we wanted in Kafka, we chosen to use the following technologies:
- Apache Kafka: Open-source distributed streaming platform that can publish and subscribe to a stream of records, similar to a message queue or messaging system.
- Kafka connect: Core component of Apache Kafka that provides scalable and resilient integration between Kafka and other systems.
- Debezium: Open-source platform for Change Data Capture from databases.
- PostgreSQL: Both databases (initial and target) were PostgreSQL in version 10.
- Wal2json, protobuf or native plugin pgoutput: logical decoding output plugin for PostgreSQL.
- Kafka connect UI: Open-source graphical interface or web tool for Kafka Connect.
- Kafka connect exporter: Open-source Prometheus exporter for Kafka Connect.
- AKHQ (previously known as KafkaHQ): Open-source web tool for Apache Kafka to manage topics.

Key concepts for database configuration
To explain the impacts on the database (represented as Database A on figure 3) and its connection with Kafka Connect, there are two important concepts to understand:
- WAL: is the short name of Write-Ahead Logging. To ensure data integrity, we should consider as a principle that all the changes to data files must be logged before the commit takes effect on the database. So, the WAL files can be defined as the PostgreSQL log of every single change that was committed. This log can be used, for example for master/slave replication or to recover the database in case of a crash.
- Logical Replication Slot: represents a stream of logical changes that can be replayed to a client in the order that they were made. Those changes are decoded row by row, even if they were produced by a single command. Because we need to extract all persistent database tables data changes in a coherent way without detailed knowledge of the database’s internal state, the logical replication slot, will allow us to plug a logical decoding output plugin for that purpose.
To be able to plug a connector to a database, we should ensure that a logical replication slot exists either created manually or automatically, depending on the output plugin chosen for the solution (wal2json, protobuf or pgoutput).
Kafka Connect connector and tasks
After deploying Kafka Connect on Kubernetes we chose to use Kafka Connect UI to easily set up the connector and the correspondent tasks that represents how data is copied to or from Kafka. The tasks have no state stored within them as it is stored in Kafka special topics managed by the connector, allowing them to be started, stopped or restarted at any time.
As soon as the connector and task configuration are finished, the connector monitors and records the row-level changes in the database. The first time that the connector connects to the database it takes a consistent snapshot of all database schemas and when completed, the connector continuously streams the changes that were committed from the exact point at which the snapshot was made.
The connector is fault-tolerant and saves the position in the WAL with each event and if it stops for any reason, after restarting it continues reading the WAL from the last event read.


Kafka topics and technical events format
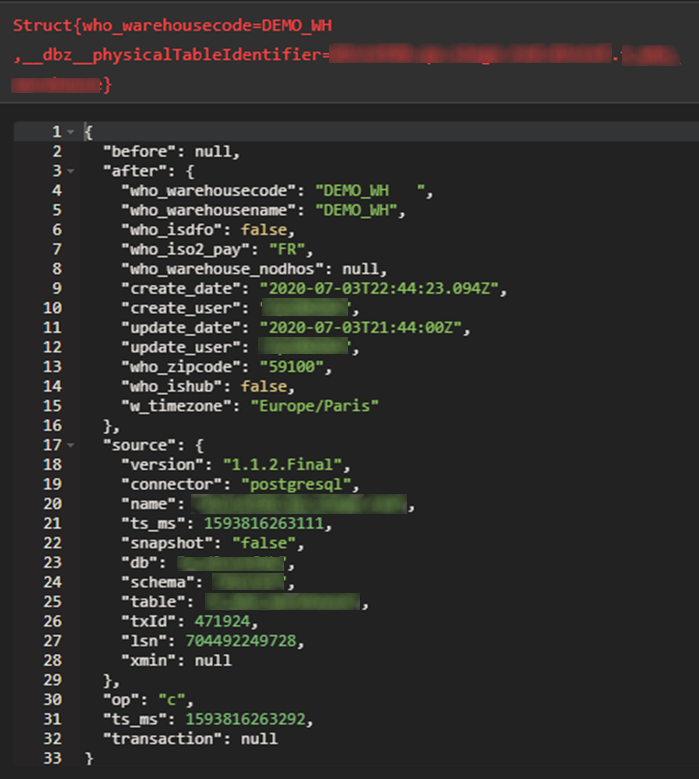
By default, the Kafka topic names will be generated using the following format: <database server>.<database schema>.<table name>
The events produced to those topics follow a pre-defined format:
- Message key: table primary key
- Message value: holds the remaining table fields
- before: contains the state of the row before the event occurred
- after: contains the state of the row after the event occurred
- source: contains a structure describing the source metadata
- op: describes the type of operation (c, u, d)
- ts_ms: contains the time at which the connector processed the event
Monitoring as a key element
Monitoring was a key element to successfully deploying this project in production.
During implementation, it was detected that once the logical replication slot is created, no WAL files will be discarded until they are consumed by Kafka Connect. In other words, the database will crash if space on the WAL folder is exhausted due to no active connector consuming data.
Implementing Kafka CDC will always require a preliminary study of how much space on WAL folder should be adopted to prevent issues in case of Kafka Connect failure.
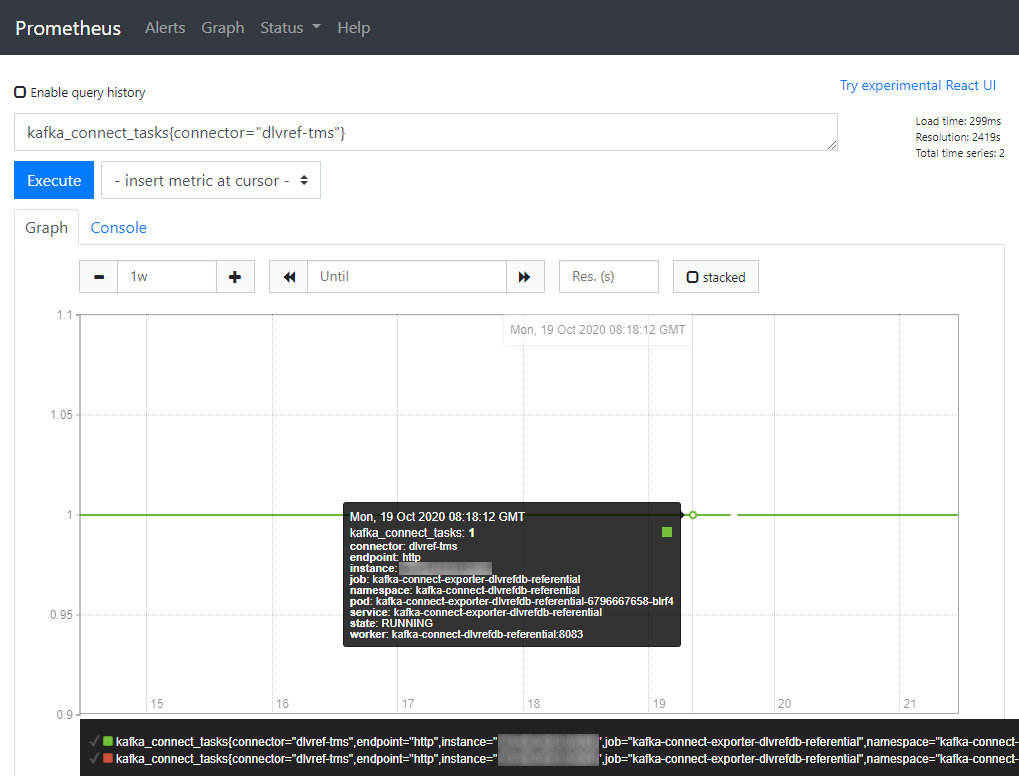
Also, proper monitoring should be implemented to detect in near-real time if the connector fails and to take the required actions to get the connector working again. To easily monitor Kafka Connect, we used Kafka Connect Exporter that exports Kafka Connect metrics to Prometheus and give us key metrics to monitor the status of the connector and associated tasks.
Constraints to be considered using Kafka Connect
Even Kafka CDC was the solution implemented for our database replication, we had to deal with some constraints. Kafka connect does not support DDL changes, so changes on database structure needs to be manually coordinated between the two databases.
Also, because we have a topic per table, it’s not possible to guaranty that we will consume the technical events on the order that they were made between topics, so we had to remove the foreign keys of the target database and only maintain the primary keys.
To finish, we should not forget, in case of issue with loss of events, how the consumers will react to the duplicated technical events, if we use the snapshot mode to recover the data lost.
Prefer business over technical events
On La Redoute, we had a second use case, where we used Kafka CDC to be able to have in near real time a business event produced by our legacy system. In this second use case, we did not allow the final business event consumers to connect directly to the technical events, produced by Kafka Connect (inside the technical topics), but instead, we created a consumer to transform the technical events on business events and to ignore the technical events not relevant to business. Choosing to have consumers connected to business events, will allow them to be decoupled from the database structure and to replace in the future the legacy system by a new solution, without any direct impact on the final consumers.
Even Kafka CDC can be very helpful during the transformation trajectory, on La Redoute we prefer to have business events instead technical events. On the use cases where Kafka CDC was the chosen solution to achieve the goal of having an event oriented to business, produced by our legacy system, we always consider the need of an extra consumer to translate the technical event in a business event.
Below there are a set of useful links for Kafka CDC investigation and used as a base for this article:
