
Migrating our Data platform from Google Cloud Platform to Azure Databricks is more than just a change of cloud providers; this is also an opportunity to build more robust and efficient foundations for a platform that will be both easy to maintain and easy to evolve.
Establishing new best practices is therefore an essential aspect of the migration as we have learned valuable lessons from the previous implementation.
Among our ongoing efforts, one of the key focuses is optimising our Python workflow. This includes dependency management, linting, formatting, and static type checking. All these aspects combined enforce reliable and maintainable code allowing us to build higher-quality solutions with increased productivity and increased confidence in our deployments.
uv, Ruff, Pyright, and pytest have become the pillars of our development process. Let’s have a closer look at how we are leveraging these tools in the Data team.
uv for extremely fast package management
Before talking about uv, it is important to introduce two key elements: a company named Astral and a programming language named Rust.
Who else than Astral themselves to better introduce their mission? As they put it on their website, their mission is “to make the Python ecosystem more productive by building high-performance developer tools”. To achieve this, their programming language of choice is Rust. This language perfectly suits this role as it is known for focusing on safety, speed and concurrency. I am not going to dive deeper into it as this beyond the scope of this article. If you’re not familiar with Rust, I encourage you to read more about it as this is a fascinating (and challenging!) language.
uv removes the complexity from Python development by unifying many important aspects in a single tool. While first designed as a replacement for pip (the standard package manager for Python), uv now offers many capabilities: Python installation, end-to-end project management, script execution with uv run, invocation of Python CLI tools without installation, among others.
To illustrate the benefits of uv in our workflow and how it leverages the power of Rust, let’s consider the installation of the databricks-connect dependency. This package allows connecting IDEs to Databricks compute. Installing it using pip via the command pip install databricks-connect takes 22 seconds. With uv using the command uv add databricks-connect, the installation takes only 2 seconds, representing approximately a 91% reduction in installation time.
This benchmark was performed on a small virtual machine for testing purposes. Results may vary depending on hardware and network conditions.
Ruff for lightning-fast linting and formatting
Ruff is also a high-performance tool from Astral leveraging the power of Rust to unify formatting and linting into a single, extremely fast tool.
To enforce clean and readable code, it is essential to implement a code formatter within our workflow. A code formatter essentially applies a set of rules to reformat the code to a consistent style. The improved readability that results simplifies working on a given project with other members of the team. Ruff is our Python code formatter of choice as it only takes a fraction of a second to format an entire codebase.
Formatting on its own is not sufficient as formatted code could still contain some errors. Linting also plays a crucial role in maintaining high quality code. A linter essentially analyses the code for various potential issues such as undefined variable or unused import for instance. Ruff is our Python linter of choice as it supports over 800 lint rules and, as with formatting, it only takes a fraction of a second to lint an entire codebase. Currently, beyond the default rules, Pyflakes (F) and pycodestyle Error (E), we are focusing on flake8-annotations (ANN), isort (I), pydocstyle (D), and pep8-naming (N) rules. For a comprehensive overview of these rules, please refer to the Ruff documentation: Rules.
Let’s have a closer look at the pydocstyle (D) rules. These rules are designed to enforce proper documentation of Python objects via the use of docstrings. For example, one of these rules is the rule D103 which states “Missing docstring in public function”. Considering the following function:

Ruff immediately flag this rule violation:
D13 Missing docstring in public
function def get_primary_key_filter(primary_key):
^^^^^^^^^^^^^^^^^ D103 if not primary_key: raise ValueError("Empty primary key")
We need to document this function with a docstring for Ruff to pass:
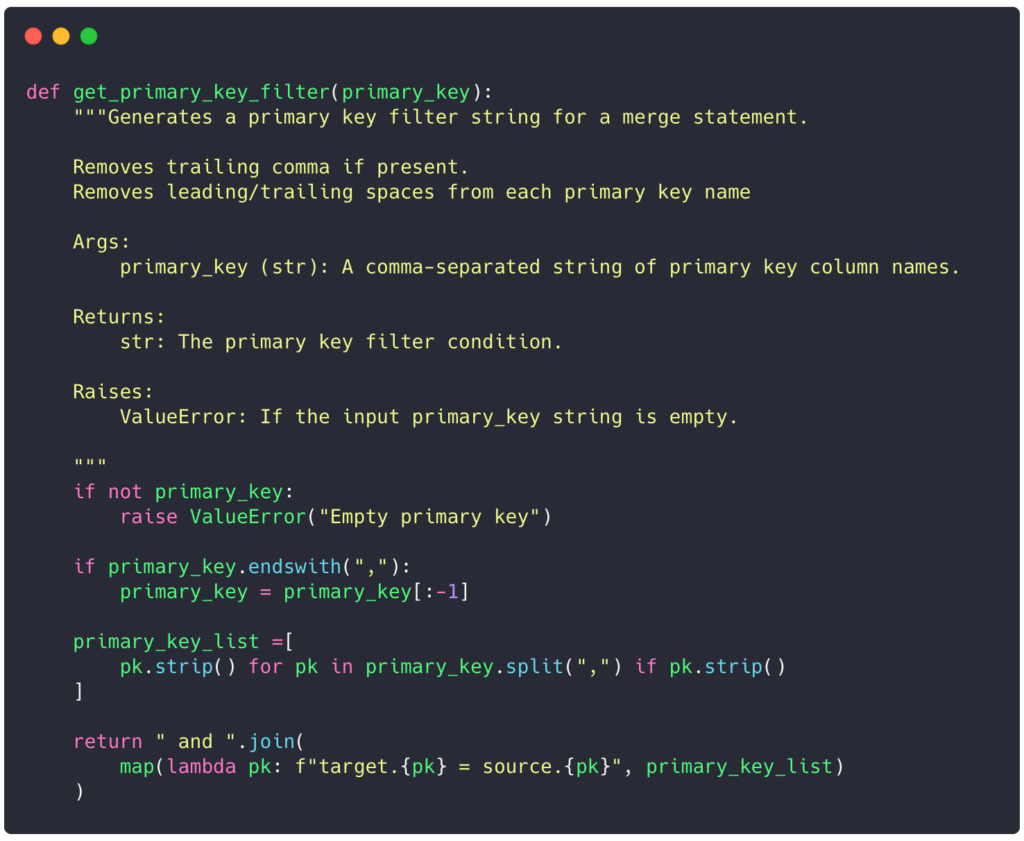
The function is now well documented, making it easier for everyone to understand what it does and how to use it, and also simplifying potential refactoring or the addition of new features.
Pyright for high-performance static type checking
While linting and formatting significantly improve our code quality, we can still go a step further to enhance our code. Our get_primary_key_filter function could still benefit from more readability and information, but let’s now consider another example.
Imagine the following function:
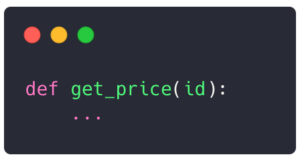
It looks like a very simple function accepting a single argument. However, we have no idea what “id” really is. It could either be an integer, a string, or even a UUID object. And we can only guess what the function returns. This lack of clarity makes this function error-prone and troublesome to use.
This is where Pyright and static type checking make their grand entrance!
Type hints were introduced to Python in version 3.5 (PEP 484) allowing users to annotate the types of their objects. Coupled with a static type checker, Pyright in our case, the types are checked before the code is actually run. While it requires more time and efforts to develop, type checking presents several advantages:
- Error detection before testing.
- Enhanced code readability and documentation.
- Improved code design and structure.
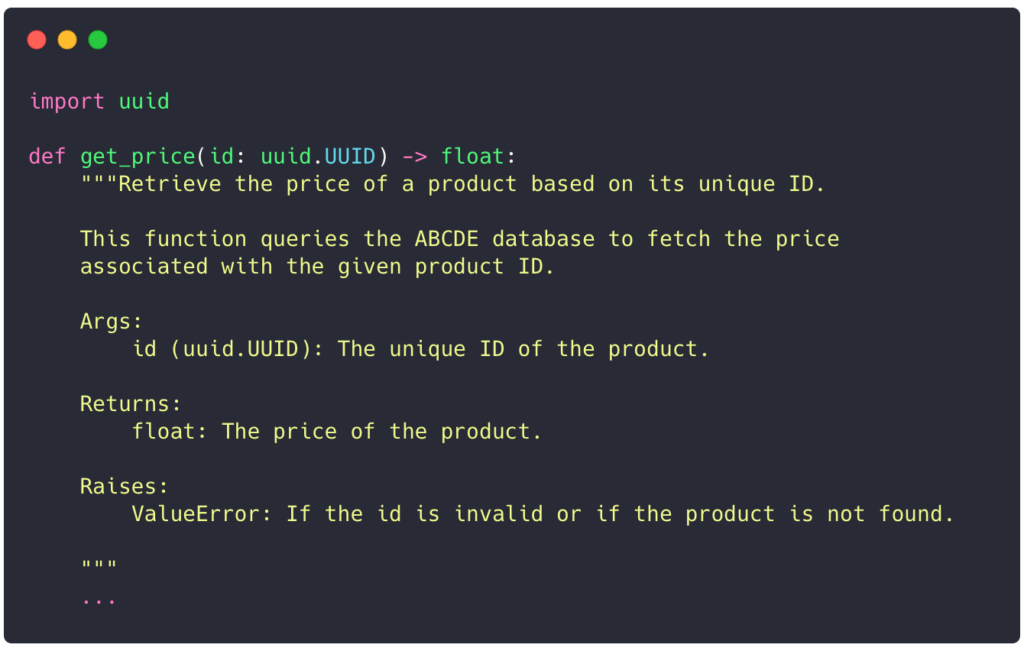
It’s time to enhance our function with the clarity it deserves thanks to type hints (and docstring!):
If someone tries to use this function with a string id, for example:
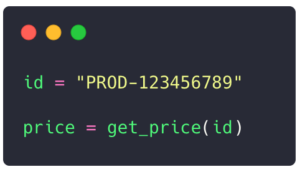
Pyright will immediately flag this error:
error: Argument of type "Literal['PROD-123456789']" cannot be assigned to parameter "id" of type "UUID" in function "get_price"
"Literal['PROD-123456789']" is not assignable to "UUID" (reportArgumentType)
1 error, 0 warnings, 0 informations
It is important to remember that these type hints are, as their name suggests, only hints and therefore have no runtime effect. In certain situations, the code may still execute without errors, even with type mismatches (for instance, truthy values in a boolean context).
Note
Charlie Marsh, the founder of Astral, recently announced that they are developing ty a new static type checker for Python. Considering how performant uv and Ruff are, I have no doubt that this new tool will be widely adopted by the community soon after its release.
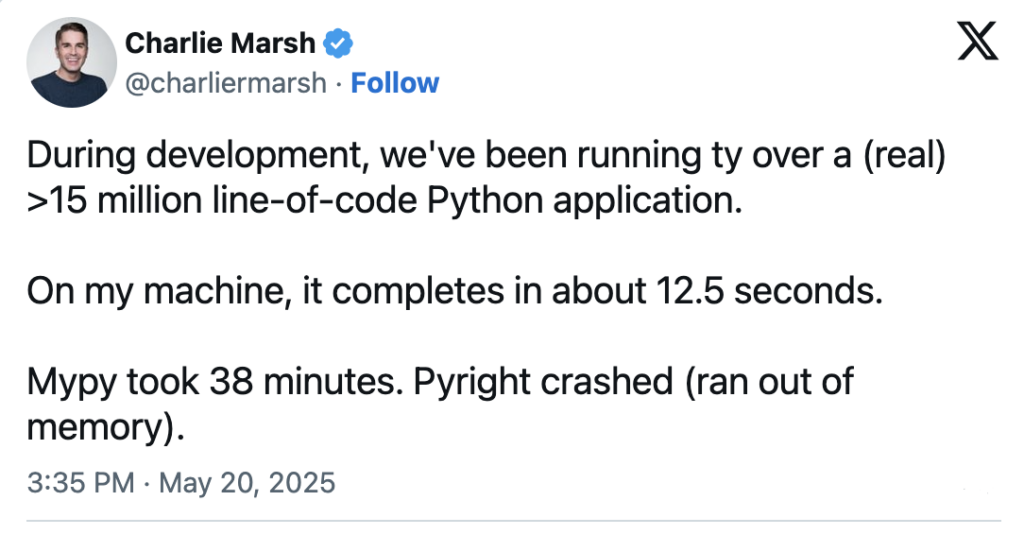
While its precise speed remains to be seen, we can confidently say that ty will speed up our CI/CD pipelines simply by eliminating the need to install npm, which is currently required to run Pyright.
pytest for efficient testing
A good linter and a good static type checker together can catch many issues before the code even runs. However, it does not ensure that the code behaves as expected. Testing becomes essential to build a reliable, maintainable and evolvable codebase. And when it comes to testing, pytest is our framework of choice.
Indeed pytest offers several benefits:
- The simple and readable syntax makes writing tests straightforward.
- The powerful assertion mechanism makes it easy to understand outcomes.
- The parametrization of tests makes it easy to write tests that share the same logic but with different inputs.
- The fixtures allow explicit declarations of test dependencies, reducing boilerplate code.
- The auto-discovery of tests simplifies test execution.
- The extensive plugin ecosystem provides a wide range of extensions designed to enhance its capabilities.
Nothing is better than an example to illustrate why tests are crucial. Consider this function that accepts a list of numbers and returns the average:
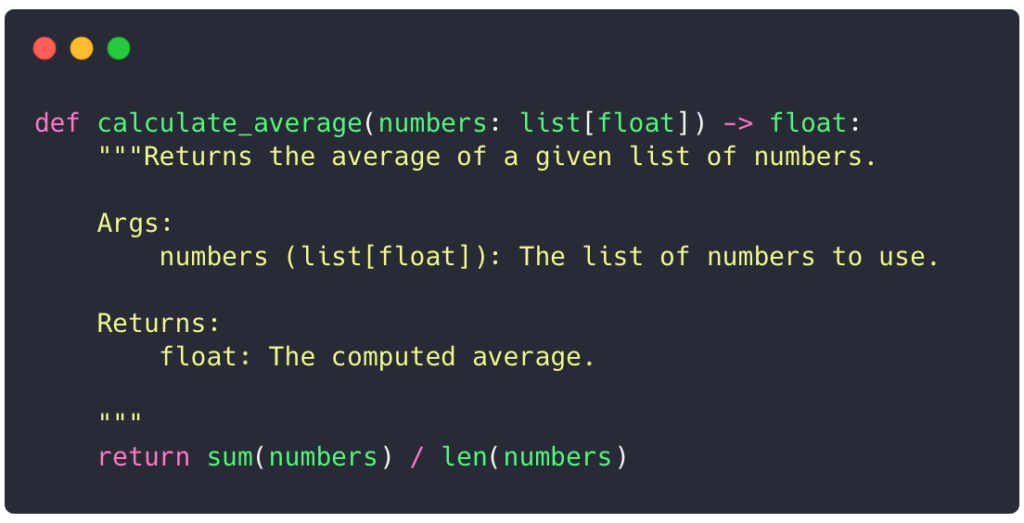
At first glance, the code seems to correctly compute the average. However, there is a subtle bug that some of you may have already noticed. Let’s write some tests to validate the function behavior.
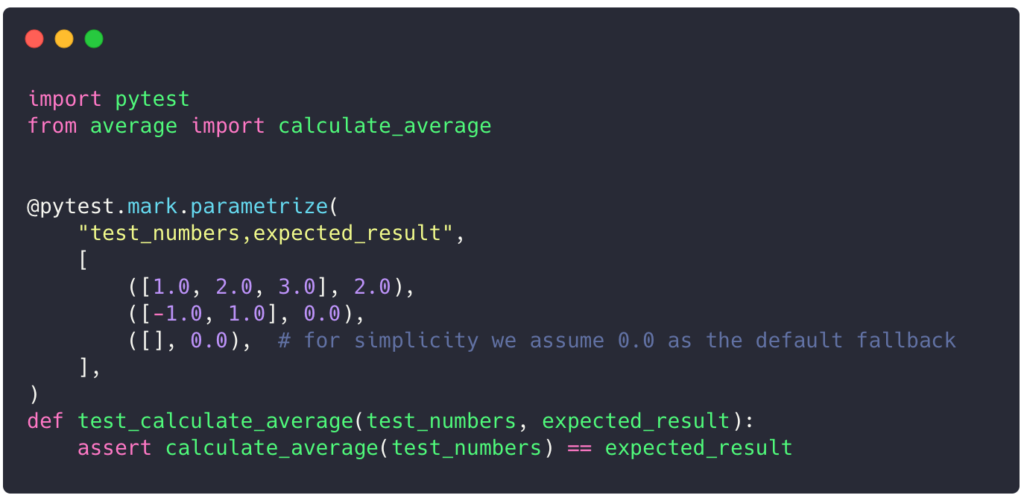
We can execute the tests by simply running uv run pytest.
pytest will immediately catch our subtle bug:
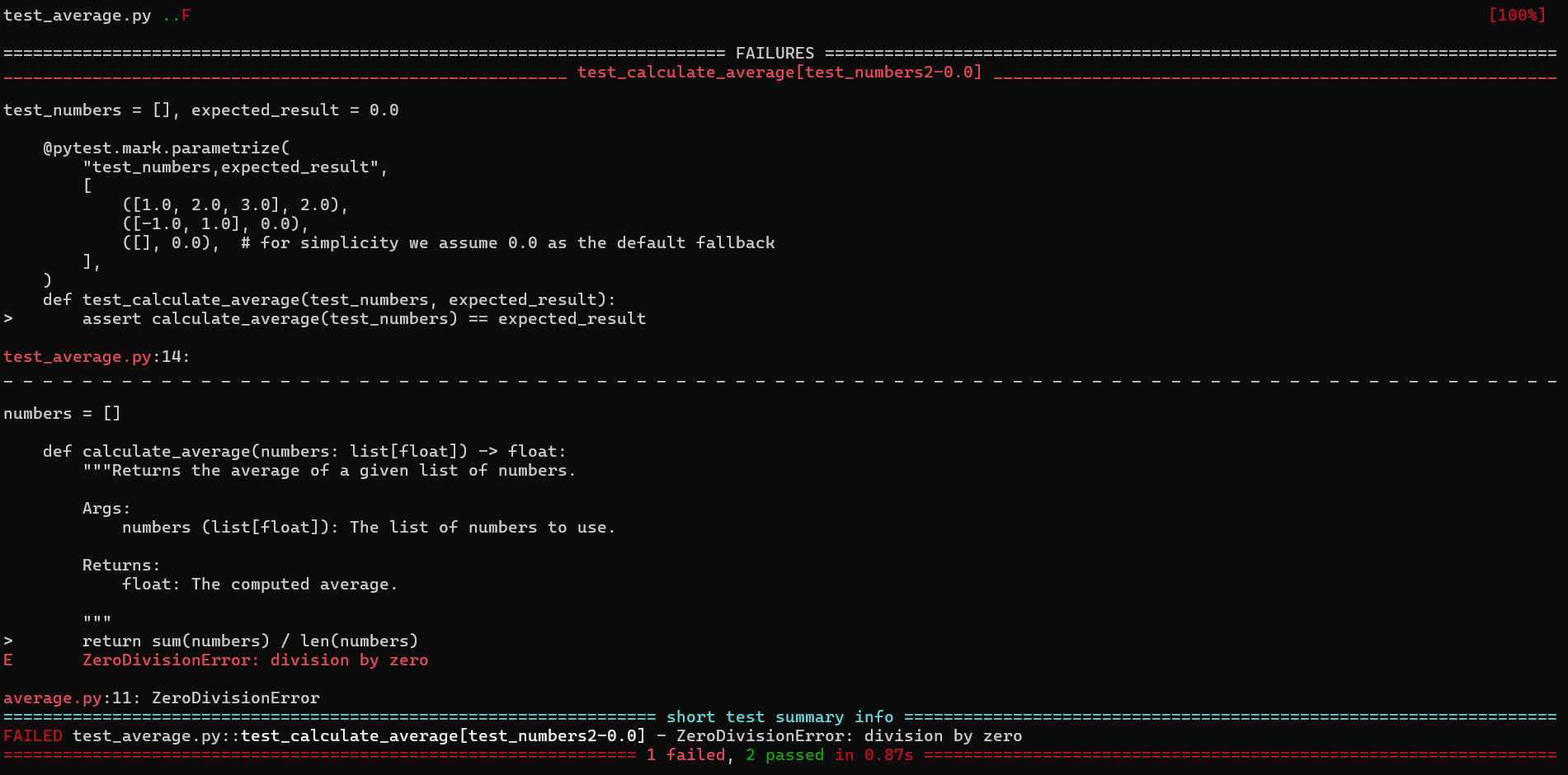
This error occurs because the len(numbers) is zero when the list is empty. We can fix this bug by adding a check for an empty list:
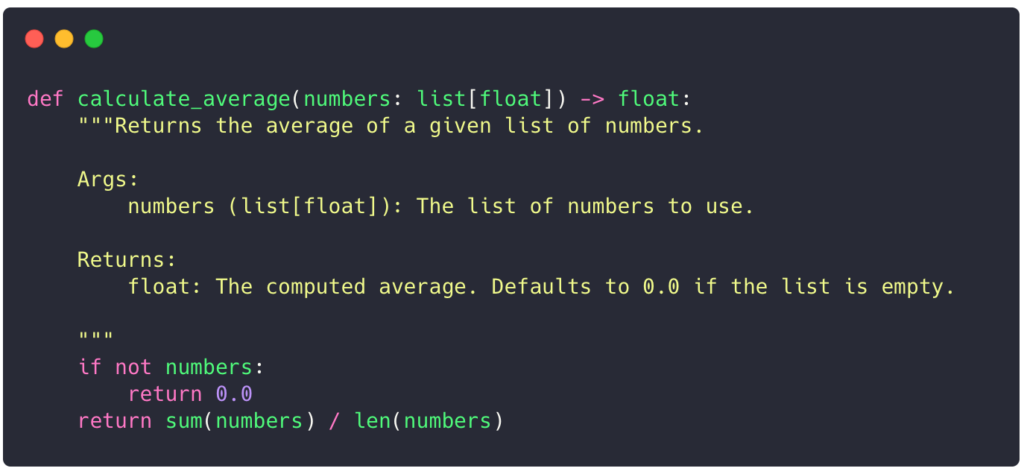
All the tests now pass! This is a good example (while short and simplified) to understand how writing tests using pytest can help us prevent errors that were not necessarily caught by Ruff or Pyright.
Integrating these tools into our IDEs for local development and within our CI/CD processes help us minimize the risk of introducing errors. This guarantees that code merged into our protected branches meets our quality criteria, making it easier to maintain and to introduce new features.
The speed improvement that offer both uv and Ruff is particularly valuable in our CI/CD pipelines, where faster executions translate to shortened feedback loop and quicker change deployments.
With these tools in place, we are on the right track to build a robust and scalable Data platform.
