
Our starting point in the Web platform delivery
Our web platform has big stakes while we were evolving the business model up to 90% of online sales. As a fashion business, it means peaks of traffic, rapid features evolution to sustain the customer experience optimization. At that time, Web releases were happening every 8 to 12 weeks, as a quarterly release. It was regularly a source of pressure, hotfixes, manual testing, impacting our customer and internal staff.
Our Definition of a Successful Platform Delivery
We first needed to define how success would look like in terms of vision and ambition. Then align the bottom-line KPIs and metrics to be able to challenge and verify our results. We decided to work on the various axis of Software Delivery Lifecycle and LEAN. We end up combining indicators of speed and quality of delivery based on the following standard indicators:
- Deployment Frequency: Number of deploys we can do in a defined timeframe. We targeted to deploy at least once per day, coming from our quarterly release.
- Lead-Time: Time to ship a feature up to production used by our customer. We defined a range of 1 hour for urgent changes to 10 hours as a maximum constraint.
- MTTR (Mean Time To Resolve): Defined as the delay to solve an issue, that do include the MTTA (Mean Time To Assign). We defined less than 1 hour for the critical incidents, impacting main business processes like order entry, customer account creation.
- Stability: Defined as the ratio of failed changes out of successful changes. We defined our Change-Failure-Rate (CFR) to stay under 10%, without rollback, always going forward.
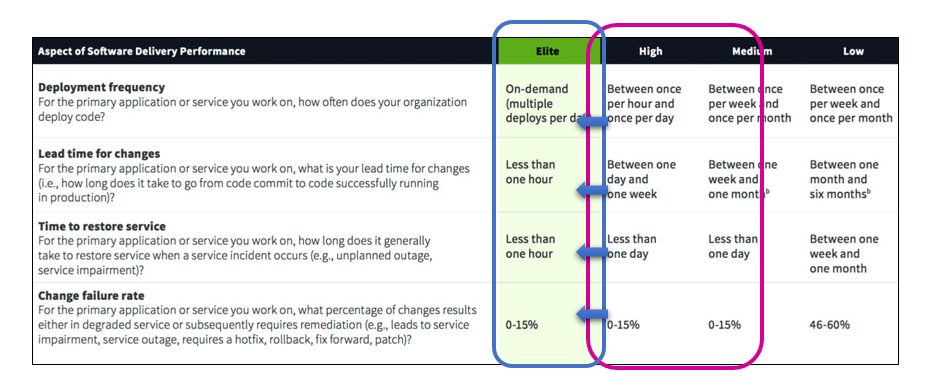
What we defined as our priorities
Our priority was to improve our performance to reach the Elite performance group. After an analysis of the situation and the limiting factors, we decided to focus on reducing the release cycle time. It required first to reduce their size and working on its testing automation. Combining those two major changes, we would be able to deliver more frequent and reliable releases.
Through the Software Delivery Lifecycle, our main pain point was on the time lost through the test and acceptance lifecycle. Those symptoms were due to a silos organization with a lot of hands-off, resulting in slow feedback loops. We were also significantly lacking a testing automation solution. The one available at that time were not supporting the entire test lifecycle.
We decided to focus on end-to-end functional testing, and to stop investing more effort on unit testing. Our unit testing are useful to validate the product architecture, not the UX. We were also convinced that end-to-end testing would better reflect the customer experience and its acceptance criteria.
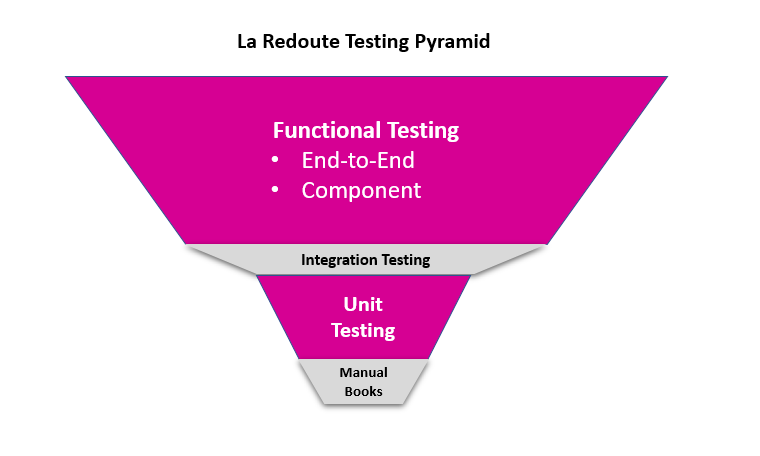
The Organization defined
The key objective was to design an organization able to deliver fast and reliable features, iterating on the test lifecycle. Therefore, we defined teams focused on specific area of the website by functional domain. We updated the roles and responsibilities between the Business, Product Owner, Developer, Tester and Ops team. They worked through a workflow to drive the implementation factually and more efficiently.
In parallel, a dedicated project team was setup to define the Test organisation within our testing solution Cerberus. It allowed the transversal teams to work and iterate together with a common tool. They were able to work on functional and technical specifications, test implementation and execution together. The key difference with the past solution was the unique and central solution allowing collaboration and fast feedback loops.
The Processes Implemented
We worked on the process that would allow us to deliver the reliable frequent changes. Our delivery is based on a trunk-development methodology. This enables smaller and simpler releases while avoiding the accidental complexity of branching. The process is defined below:
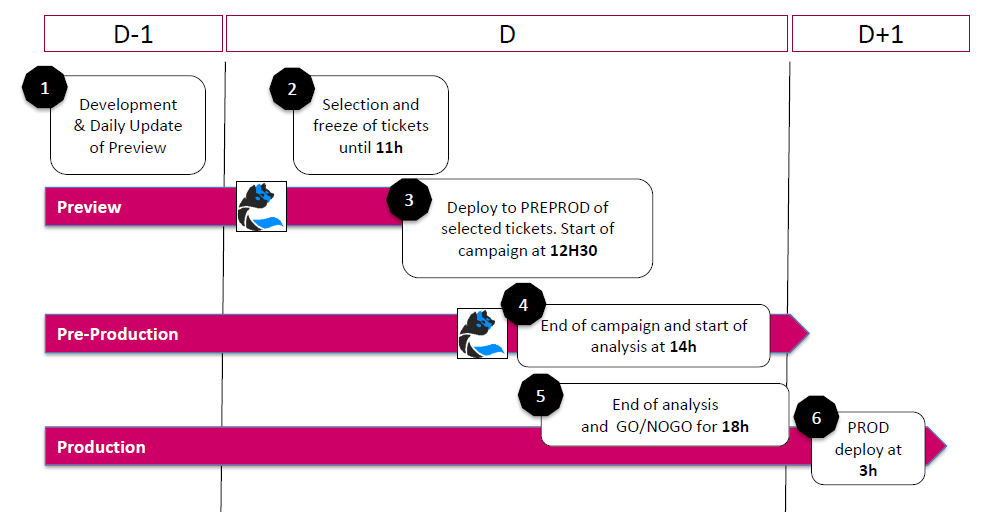
We started with the non-production environments refresh every day in an automated and systematic way. Straight after that, a test campaign is triggered automatically to get confidence in the platform stability and detect potential bugs from the previous day coding. Then, we have until 11 a.m. to incorporate last features and fixes in the trunk, with tests. Then the platform is built, deployed to the Pre-Production environment, with a full end-to-end automated test campaign launched. It then let us a maximum of 4 hours to decide which features to keep activated or not. We then give a GO/NOGO on their defined scope of features. The deploy is then still done at night in an automated way, to guarantee stability. The defined process also got a rapid lane for exceptional hot-fixes. We know it is at risk as not able to perform necessarily the full test suite.
Our Results and Retrospective
This organization, process and tools allowed us over the year reach over 6,000 cross-devices automated tests, with a minimal team of 3 testers. We first reached a plateau of 2,000 tests, that increased the two following years. As the tool works with library of data, actions and controls, we can easily change the behavior for a set of tests. During the project, systematic processes were also defined as critical for continuous improvement. For instance, implementing an automated test for each feature or bug request.
Automated Testing support both Delivery & Production performance
Taking a step back to our performance versus our initial expectations, we were able to reach our initial ambition of having a daily release. In terms of MTTR, we also reach our objective of resolving in less than 1 hour the critical incidents. We can detect abnormal behavior using automated tests that are always running in production to simulate real customers. It allows to quickly react, either fixing or toggling off the feature. In terms of stability, we are currently ranging between 93 and 97% successful delivery, having only minor cases where we overpass the change failed rate.
Automated Testing is a Product Continuous Effort, not a One-shot Project
Our current priorities are related to adapting the test suite to the new usages on mobile devices and new interfaces. In parallel, we are working on reducing the lead-time on tests reliability and execution. The main actions are related to automating flaky tests fixing and on moving to an auto-scaled container environment.
We shared our experience at various conferences, namely Open Source Portugal and Testing Portugal, feel free to contact us for more information or organize a community sharing.
