
Architecture evolved to accelerate software delivery
Existing companies usually rely on a mix of architecture patterns they are transforming towards modern technological foundations.
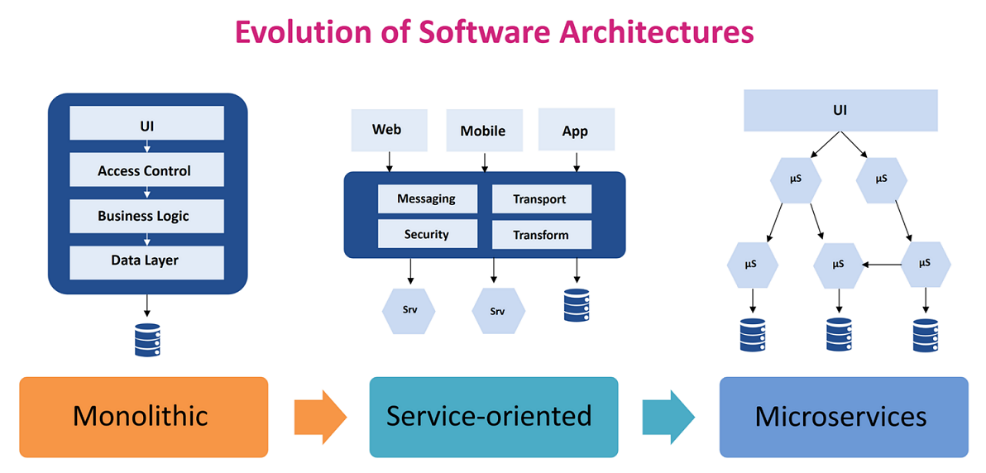
The traditional Monolith architecture coming from the ’80s supports robust transactions but tends to become highly complex to understand, maintain and evolve.
SOA appears as a rescue to those problems, relying on reusable and distributed services to dilute the complexity. Hence, having a high degree of synchronous and orchestrated services, the overall coupling creates delivery dependencies.
This is where Microservices appear as a possible improvement when supported by a decoupled architecture such as event-driven.
More fine-grained architectures are appearing such as Function as a Service (FaaS). Being in an initial maturity phase, we do not consider them for now.
Why we decided to adopt event-driven microservices
Our architecture was mainly SOA based in 2017 after years of transformation. During that period, the focus was on removing the Mainframe dependency.
This is where we heavily relied on ESB and Integration patterns such as orchestration.
Over-time, this type of architecture led to quite a high coupling between components, that became complex to evolve.
Even if we had several properly decoupled applications, we had to evolve our practices.
In the meanwhile, microservices have emerged from early adopters, sharing their potential benefits over existing architectures.
In our context, we had competencies in distributed systems, messaging, and web services. Our driver was to accelerate software delivery while addressing our coupling issue.
Moving to an Event-Driven Microservices type architecture was the best path for us. We decided to use Kafka as the messaging platform, we have a 101 Apache Kafka article available here.
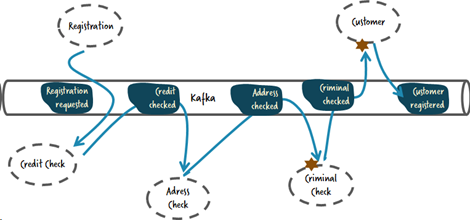
While the number of components was going to significantly increase, we were clear that automation was a requirement for this type of architecture.
Having already a set of CI/CD pipelines in Jenkins for most of our services, we were ready to leverage this experience.
At that time, we had to define which technology platforms could support our architecture.
How we structured the choice for the supporting technological platform
The globalization, Internet, and communication technologies have accelerated the number of players, products, and services available.
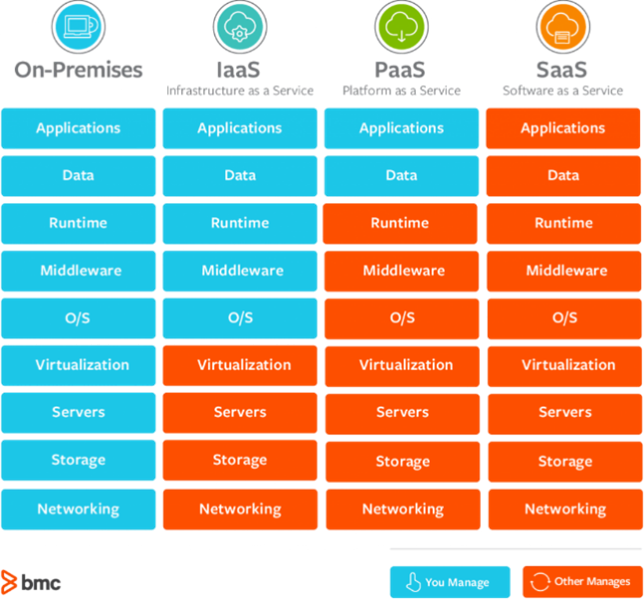
Solutions can be open-sourced, paid, or hybrid. They can be provided at the various levels: IaaS, PaaS, SaaS.
They can be hosted on an on-premise data center, a public cloud, or hybrid scenarios. Some solutions can be supported by open standards providing more flexibility, while others linked to vendors can be optimized at the cost of lock-in.
For us, our main requirements were to:
1) Enable self-service deployment of event-driven microservices, at the cost of developer on boarding and automation mainly with Infrastructure as Code
2) Be supported by the community and ecosystem, at the cost of not having a specific vendor support
3) Be available as a service with an open standard at the cost of the service price
4) Be portable across various cloud providers over-time at the cost of a specific vendor optimized solution
5) Horizontally scalable to respond to business peaks over a precise cost forecast
6) Integrates with our existing tooling such as monitoring, alerting, and ticketing at the cost of integration
Why we decided to adopt Kubernetes and containerized applications
We first looked at the application packaging for microservices, which required to be portable, scalable, supported, open, and with automation.
We were used to deploying in traditional application servers such as Tomcat.
One scenario could have been to keep the application server but leverage the IaaS capability and automation to scale. In fact, for some players, this is the only way to scale up to the required demand.
As we were searching for self-service, scalability, and portability, we consider looking at containers with Docker. It quickly revealed to be an interesting packaging for its isolation, abstraction layer, and portability.
These were in fact the true differentiators that made us seriously consider this option.
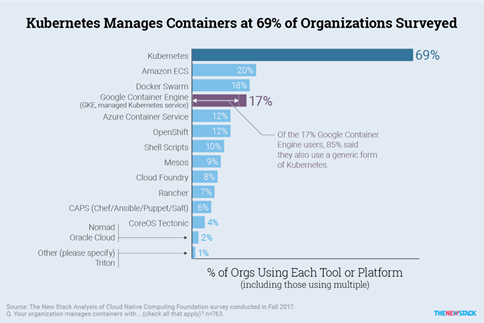
Consequently, we evaluated container orchestrators available: Kubernetes and Docker Swarm.
After a technical evaluation, the ecosystem was clearly adopting Kubernetes as the de-facto standard with the number of deployments and CNCF landscape.
Additionally, Kubernetes revealed to be made for large deployments and scalability requirements.
But for our size and scalability volumes, we probably did not require the Kubernetes expansion capability. In addition, we wanted a portable solution supported by the ecosystem.
So we decided to adopt Kubernetes at the cost of an additional complexity we had experienced.
How the infrastructure layers also had to support our platform requirements
Being clear on what we wanted to deploy, we then looked at the supporting infrastructure layers.
We were used to relying on virtual machines, not truly in IaaS as lacking the automation ecosystem.
Searching for automation, scalability, and on-demand models, a public cloud solution was the most appropriate.
We had then two main choices available to host our container orchestrator: IaaS or PaaS.
We were looking for reduced administration overhead while using the right tool to operate our applications.
So we favored a PaaS solution over an IaaS one to access a managed container orchestration platform.
We were at that point confronted with choosing a public PaaS orchestration platform.
The main options were to use a specific cloud vendor solution (GKE, EKS, …) or a more abstracted one (Kubernetes as a Service platform or fully managed like Pivotal Cloud Foundry). Be cloud-agnostic was a key driver for us and made us select Kubernetes.
For KaaS models, we judged the extra cost not justifying its investment, while for other managed platforms, the lock-in was too high.
Our cloud adoption started with Google Cloud Platform, so we made the choice of Google Kubernetes Engine (GKE).
What we learned during our exploration and selection journey
Taking a step back through our decision-making process, a series of practices emerge that we can share for a similar context.
First, the clarification of the problem to be solved in your context is a key pre-requisite. It helps you envision what you are really trying to achieve, before rushing to possible solutions.
Secondly, articulating your requirements helps to get the big picture view of the various factors to consider.
You can at that stage avoid common pitfalls that can question your choice later.
Then, as you start identifying possible solutions, having your criteria defined enables you to clarify which trade-offs you would accept in your context.
This is key to align your stakeholders and ensure your project delivery.

The choice of Kubernetes has been made for some time now, we are satisfied with this decision and its implementation over-time, responding to the objectives we had.
In the next article, we will share our experience and learning after running one year in production. Stay tuned!
References
Figure 1: Software Architecture Evolution link
Figure 2: Event-Driven Microservices Example link
Figure 3: SaaS models: link
Figure 4: Kubernetes within the CNCF landscape link
Figure 5: Typical PaaS functions link
InfoQ and AirBnb Kubernetes Services link
