
The evergrowing data and the need for real-time processing
About a decade ago the term “real-time data processing” started to come about when companies started to realize the large amount of data generated. For example, customer activity on a website, the amount of clicks, the more requested items, the most used search words, etc.
This data was handled by logging aggregation solutions that consolidated it into a single and centralized platform so that it could be reviewed and analyzed.
Although this solution solved the problem for dealing with the evergrowing amount of data and providing it to offline analysis systems like Hadoop, it offered few possibilities for building real-time processing systems. With more and more people accessing the Internet and especially shopping through the Internet, analyzing those clicks and searches in real-time was starting to become crucial to develop and improve any online business.

Where it all began
About 10 years ago, a team at LinkedIn that included Jay Kreps, Jun Rao, and Neha Narkhede were searching for systems that could satisfy their need to centralize the data coming in and analyze it in real time. The options existed in the market but none of them really fit the criteria for what they were searching for.
After exploring the possibilities at hand, this team decided to solve their issues on their own. They developed a tool that would later become very popular and extremely useful to companies world-wide. This tool was named Apache Kafka®.
Most of the team responsible for the creation of this tool after a while left LinkedIn to start their own company: Confluent, that is centered around Kafka and aims to help companies that want to make the transition to Kafka from other traditional systems.

What is Kafka? What I it used for?
Apache Kafka® is a distributed streaming platform and is written in Scala and Java.
Kafka aims at providing a high-throughput, low-latency platform for handling real-time data feeds.
This streaming platform is capable of storing, publishing and subscribing to streams of records and process those streams as they occur.
It’s mainly used for two broad classes of applications:
- Build real time streaming data pipelines that reliably get data between systems
- Build real-time streaming applications that transform or react to the streams of data.

How does Kafka work?
Kafka runs as a cluster on one or more servers that can span in multiple datacenters.
This cluster stores streams of records in categories called topics and each record has a key, a value and a timestamp.
In Kafka’s world we have Producers, that is, any application or system that is responsible for choosing and publish data to a certain topic in Kafka.
There are Consumers, which subscribe to a topic of their choice and get any data that comes into that topic.
We also have stream processors that are applications that transform input Kafka topics into output Kafka topics in near real-time. Confluent provides a very useful library that helps developers to build these applications in an easier way called Kafka Streams.
Confluent also provides companies with connectors that allows developers and engineers to access and deliver data to connect an organization’s applications with their event streaming platform.
If for any reason, all the information above didn’t help to clear out what Kafka is and what it does we can try to make an analogy of its functionality with bread.
Yes, bread.

Kafka and the Bakery Analogy
Imagine a bakery that bakes bread every day (our data events). This bread comes out the oven and its put-on trays waiting until a van comes to pick it up every few hours.
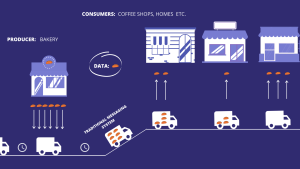
In this case the bakery is our producer and the van correspond to our traditional message distribution system.
The bread is then distributed by the van to different coffee shops, homes etc. (the consumers)
This method of delivery works great but there are some aspects that can be improved. First off, imagine if a coffee shop runs out of bread and wants a new order as soon as possible due to increased demand. With the van as the transporting system the order takes time to come in and the coffee shop loses possible sales.
The other aspect is that the bread must sit in the bakery trays for a while before the van comes in. It arrives cold and dry sometimes, it’s not the same as eating bread straight out the oven.
To solve these issues why don’t we replace that old dusty van with a bullet train with infinite carriages?
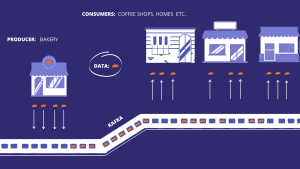
Yes, a bullet train that never ends.
With this train, the bread comes straight out the oven and its loaded straight into a new empty carriage, (that can only have one type of bread each) (topics) and it arrives at its consumers almost immediately.
It’s the same thing with Kafka. Kafka (the train) replaces traditional messaging systems that work with batch processes ( the van) and allows data (the bread) produced to its topics (the carriages) to be available to process in real time (hot bread straight out the oven).
If that analogy did not work for you or you still want to know more about Kafka and what it offers in more detail you can find more information here: https://kafka.apache.org/
We also have a dedicated article on KSQL on “Why, How and When to use” : https://laredoute.io/blog/why-how-and-when-to-use-ksql/
References
Subscription.packtpub.com. 2020. Kafka Use Cases. [online] Available at: https://subscription.packtpub.com/book/big_data_and_business_intelligence/9781784393090/1/ch01lvl1sec10/kafka-use-cases
Harris, D., Signoretti, E., Signoretti, E., Baltisberger, J., Reese, B. and Signoretti, E., 2020. The Team That Created Kafka Is Leaving Linkedin To Build A Company Around It – Gigaom. [online] Gigaom.com. Available at: https://gigaom.com/2014/11/06/the-team-that-created-kafka-is-leaving-linkedin-to-build-a-company-around-it/
TechBeacon. 2020. What Is Apache Kafka? Why Is It So Popular? Should I Use It?. [online] Available at: https://techbeacon.com/app-dev-testing/what-apache-kafka-why-it-so-popular-should-you-use-it