
The transformation context
The existing system was a pure legacy one, based on Mainframe technology with its inherent batches and monolith architecture-style. The new architecture was based on various systems, that were clearly distributed, for commercial stock, transporters management, product referential, order processing, order fulfilment, and WMS. We also had the requirements to manage the activity of the various countries and entities, with different model B2B and B2C, thus increasing the complexity of the requirements.
How we start to design the system and its interactions
The pre-liminary work was done focused on delimiting the bounded-context and tied functions for each system, in order to clarify the responsibilities and then be able to map the necessary data flows and interactions between the systems. Each interaction has to identify its business events exchanges, request/response model and scenarios, and also defining its functional and non-functional requirements.
The major challenge being to limit as possible the need for synchronous exchanges where it was not needed, implementing Near-Real Time (NRT) flows. We ended-up with the list of events cascading through the system in order to define the critical path from order to parcel, it gave us a clear picture of the business implementation through the applications, and the necessity to secure those data flows.
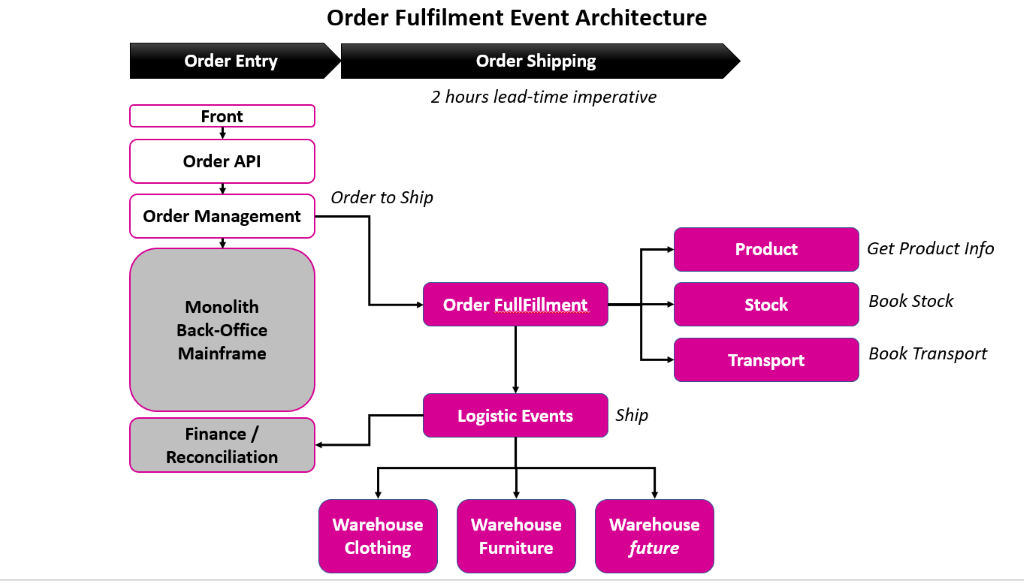
Our approach to Integration and Testing
Parallel to each system implementation, we focused our effort on end-to-end order to parcel processing, for one country and most simple case. Being a distributed architecture built in parallel, we had a lot of rework, surprises, and failures to learn more and iterate on.
The end-to-end integration and testing were our most significant effort during the implementation, but was the only way to guarantee expected behaviour, data integrity and retro-compatibility with legacy and downstream systems, mainly for accounting, finance, and reconciliation.

How we align the business behaviour and system design
The main design principles we decided to apply to satisfy the requirements and constraints were mainly based on Event-Driven Architecture (EDA), allowing us to process events in parallel, scale easier, and more resilient for error, retry management, in a distributed system.
The final implementation resulted in about 30 events representing the major interactions between all systems in order to process an order to a parcel, not counting the internal state and events of each applications, only the interfaces between systems.
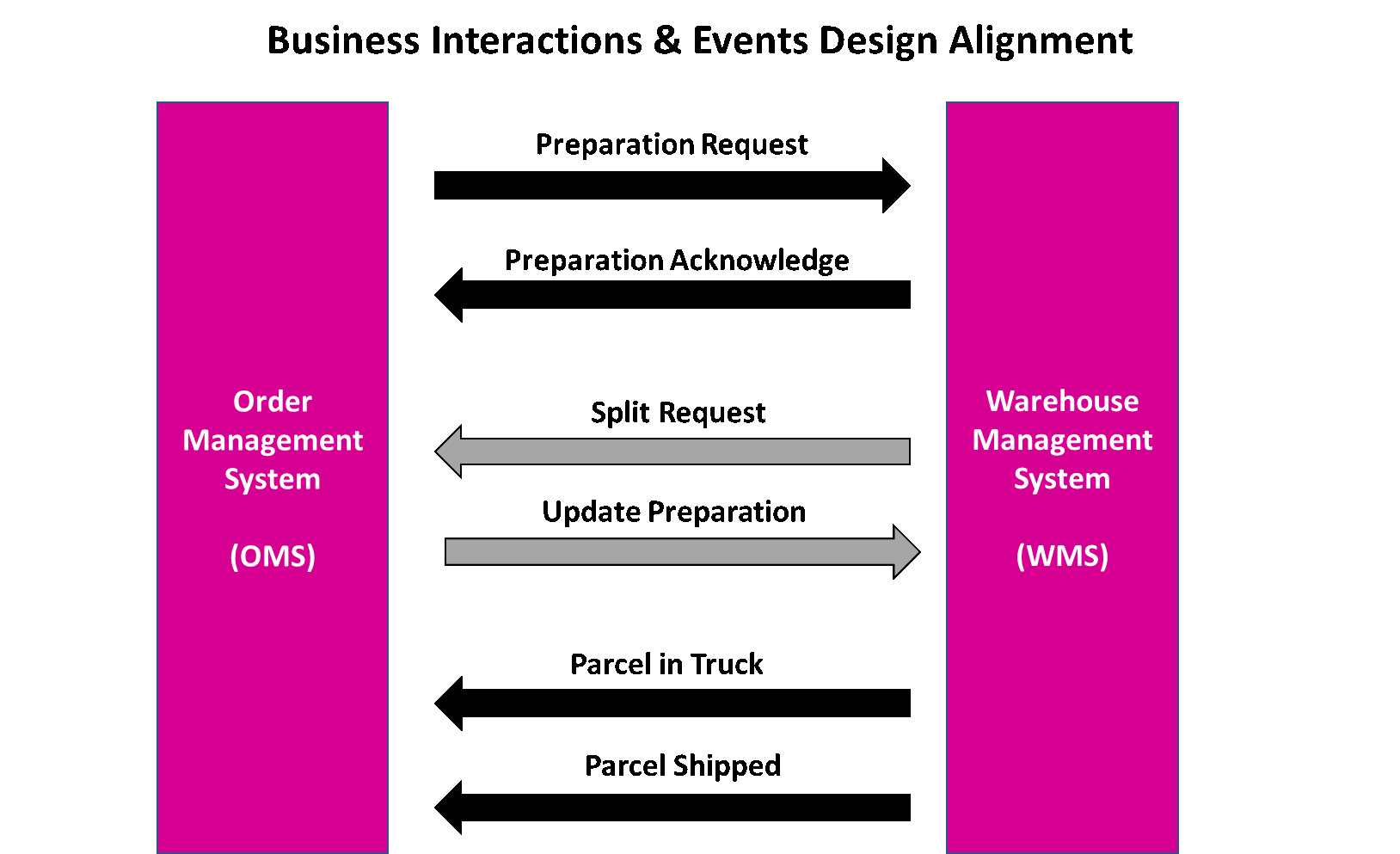
It represented a huge effort of integration, coordination as we were moving the parts in parallel and a complexity of functional use-cases. In addition, being late in addressing the monitoring and visibility topic, we did pass a significant time in ensuring the correct system behaviour and anomaly detection first manually in reactive mode, before implementing proper end-to-end observability.
Our approach to testing was for each team to perform integration testing of its individual components based on the events behaviours and invest a major part of our effort on end-to-end testing from a customer order to a customers shipment and invoicing. Only our end-to-end testing gave us the confidence to deploy in production the new systems.
Our main learnings through the transformation journey
The main learnings we can share on this major transformation, are related to cultural, organisational and technical practices.
On the agility part, the major practice we could have use better is related to the “Fail-Fast” approach, to speed our learning path, with limiting work in progress / complexity, in order to have really fast cycle time and adaptation, increasing the value delivery velocity. We did have ambition, pressure and failed to recognize either the need to delay some topics, allocate more resources to others, and design better other ones.
In terms of architecture, we also failed in the implementation rush trap, implementing with too much confidence components we had to redesign properly later, losing time later in integration, testing, correction. We do learn that investing time in defining the functional and non-functional requirements, constraints, pushing for reactive asynchronous model, can save us a lot of time in the execution, investing time in thinking and design properly.
Last, in terms of technologies, as the integration and complexity risk was really high, we should have limit our technical choice only to known and matured technology in our organisation and partners. In those stressful periods, we saw all the limit of our existing processes in terms of Testing, Automation, Monitoring, Logging, so we did clarify and prioritized better our internal roadmaps, communities of practices to be as ready as possible for major transformation challenge.
