
Data Engineering plays a crucial role in enabling organizations to harness the power of data for decision-making and insights. Test Driven Development (TDD) is a software development approach that has gained popularity for its ability to improve code quality and maintainability. In this blog post, we will explore the application of TDD in Data Engineering, highlighting its benefits, challenges, and potential pitfalls.
Data Engineering encompasses various layers, from data ingestion to integration and exposition. Each layer presents unique challenges and requirements that need to be addressed to ensure reliable data processing and analysis.
The primary objective of applying TDD in Data Engineering is to ensure the reliability and accuracy of data pipelines. By adopting a test-first approach, engineers can identify and rectify issues early in the development process, leading to more robust and maintainable code.
Implementing TDD in Data Engineering offers several advantages for businesses:
• Improved Data Quality: TDD helps in defining an interface contract for the ingestion layer, which outlines the expected data format and structure. By comparing received files against this contract before any development, data quality issues can be detected and resolved early on.
• Early Detection of Integration issues: Integration tests play a vital role in ensuring the smooth functioning of data pipelines. By conducting unit tests on each component with predefined business rules and non-regression tests, potential issues arising from source updates or additions can be identified early, preventing data processing problems.
• Enhanced Reliability: TDD encourages the creation of comprehensive unit tests for business logic. By relying on predefined unit tests rather than testing based on user experience, the risk of overlooking critical functionalities or introducing bugs decreases, leading to more reliable data processing.
The following blog post summarizes basic tests that can be setup while developing or updating data pipelines. All the tests are divided between the above mentioned 3 layers: ingestion layer, integration layer, and exposition layer. In all those cases, the practices are summarized across 3 different categories:
• The Good: what is recommended to be done in order to properly test and validate the various layers of your data pipelines
• The Bad: what is recommended not to be done, or general anti patterns
• The Ugly: what is commonly made, which is not that bad, but could be improved upon by the usage of best practices
The myth of full coverage

A web comic from xkcd explaining how fragile data pipelines are, due to dependencies and evolving data
In the realm of Data Engineering, ensuring the reliability and accuracy of data pipelines is paramount. TDD has emerged as a valuable approach to enhance code quality and maintainability. However, the concept of achieving full coverage in Data Engineering testing is often misunderstood. Full coverage, in the context of Data Engineering testing, refers to the idea of testing every aspect of a data pipeline from end to end, from source data to all dashboards. While it may sound ideal, achieving full coverage in practice is a daunting task due to the unique complexities of data pipelines:
• Scale and Complexity: Data pipelines can involve a multitude of data sources, transformations, and destinations. The sheer scale and complexity make it virtually impossible to test every component and scenario exhaustively. With large volumes of data and intricate processing logic, attempting to achieve full coverage becomes a time-consuming and resource-intensive endeavor often bringing diminishing returns or little return on investment.
• Dynamic and Evolving Data: Data pipelines often deal with dynamic and ever-changing data. New data sources may be added, existing sources may be modified, and data formats can evolve over time. Keeping up with these changes and ensuring full coverage in testing becomes a moving target. It requires continuous effort and adaptability to adjust tests accordingly.
• Resource Limitations: Testing every possible scenario can require substantial computational resources and time. Data Engineering systems often operate on extensive datasets and involve complex transformations, making it impractical to execute exhaustive tests within limited time frames. Balancing the need for thorough testing with practical resource constraints becomes a significant challenge.
Rather than striving for an unattainable goal of full coverage, it is more practical and effective to focus on critical areas within the data pipeline. Identifying these areas involves a combination of domain expertise, risk assessment, and business priorities. By prioritizing testing efforts based on criticality, time and resources can be allocated to areas where potential issues may have the most significant impact.
To achieve meaningful testing coverage, data engineers should adopt a targeted and risk-based approach. This involves identifying high-risk components, complex transformations, data quality checks, and critical business rules. By developing targeted tests for these areas, engineers can focus their efforts on ensuring the most critical aspects of the data pipeline are thoroughly tested.
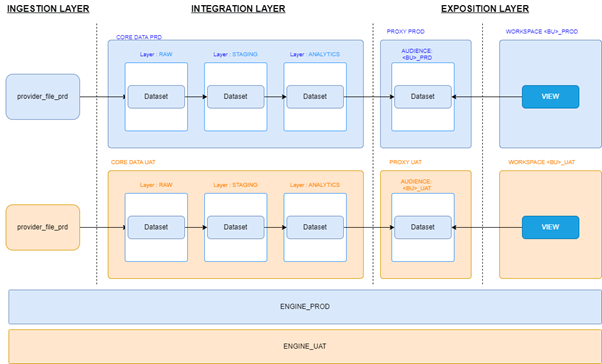
Here is an abstract representation of a data platform, with the three main layers we further describe
Ingestion tests – The foundation of Data Quality
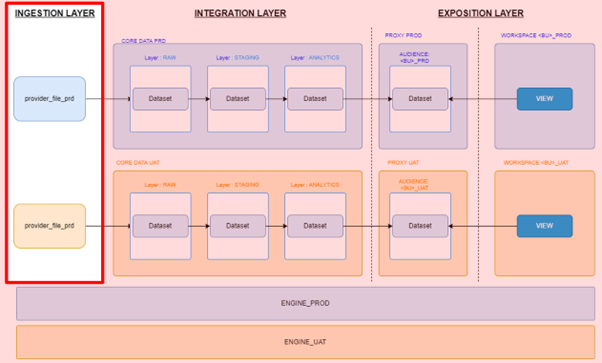
A focus on the ingestion layer, i.e. where one receives raw data such as files
The ingestion layer is the entry point for data into the system. It involves processes and mechanisms to receive, validate, and store data from various sources. Understanding the intricacies of the ingestion layer is crucial for ensuring data integrity and consistency throughout the data pipeline.
To ensure seamless data ingestion, defining an interface contract that outlines the expected format, structure, and quality of the received data is essential. This contract acts as a reference point for comparing incoming data against expectations, allowing early detection of data quality issues. The interface contract should capture details such as data types, field constraints, data ranges, and any specific business rules that need to be enforced.
The Good: defining interface contracts early on
Before any development takes place, ingestion tests focus on comparing received files against the defined interface contract. This step allows data engineers to identify discrepancies and potential data quality issues upfront, reducing the risk of propagating errors throughout the pipeline. By comparing the received data with the expected format and content, it becomes easier to identify any anomalies or inconsistencies that require resolution.
The Bad: starting development without interface contract
One common mistake is to start development on a User Acceptance Testing (UAT) environment without agreeing on the interface contract. The development process may deviate from the desired outcome without a clear understanding and alignment on the expected data format and quality. This can lead to confusion, rework, and delays in delivering a reliable data pipeline.
Developing from a UAT source data when there is a pre-production or production environment can introduce significant risks. The schema or data itself may differ between environments, leading to inconsistencies and unexpected behavior. It is essential to align development efforts with the appropriate environment to ensure accurate testing and seamless deployment.
The Ugly: defining the interface contract by yourself
Furthermore, defining an interface contract based solely on the first files received, without any agreement or collaboration, undermines the very essence of a contract. An interface contract should be a mutually agreed-upon definition that sets clear expectations for data structure, quality, and business rules. Relying on ad-hoc or implicit agreements can result in misunderstandings, inconsistencies, and challenges in maintaining data quality over time.
Integration tests – Ensuring data processing integrity
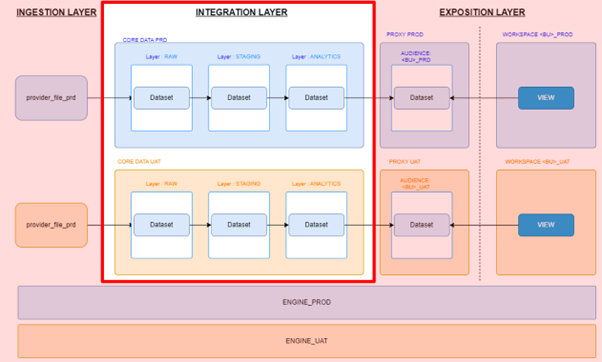
A focus on the integration layer, where one process and integrate the data that is later consumed
We now turn our attention to integration tests. The integration layer plays a critical role in data processing, encompassing raw and analytic integrations. By focusing on data types, loading mechanisms, and business rule validations, integration tests help ensure the seamless and accurate integration of data within the pipeline. In this part, we will delve deeper into the details of integration testing and highlight common pitfalls to avoid.
The integration layer in Data Engineering involves the merging, transformation, and consolidation of data from various sources. It is where different data streams come together and form the basis for subsequent analysis and decision-making. Understanding the nuances of the integration layer is key to maintaining data processing integrity.
The Good: applying integration tests based on technical requirements
Raw integration tests primarily focus on ensuring that the data types align with expectations and that the loading mechanisms function as intended. This involves validating that the incoming data matches the expected formats and adheres to defined data schemas. By conducting thorough tests at this stage, data engineers can identify any data type inconsistencies or loading issues that may affect downstream processes.
Analytic integration tests aim to validate the proper functioning of each component within the integration layer, particularly regarding business rules. Unit tests should be created for every part of the integration that involves business logic. These tests ensure that each component operates correctly and produces the desired outcomes.
Non-regression tests are crucial when a data source is updated or when a new source is added. These tests help ensure that modifications or additions to the data sources do not adversely impact the overall data processing flow. By conducting non-regression tests, data engineers can identify any unintended consequences or regressions that may have occurred due to changes in the data sources.
The Bad: going on gut feeling
One common mistake is testing business rules based solely on user experience rather than using predefined unit tests. Relying exclusively on user experience for validation may overlook critical aspects of the data processing flow and increase the risk of missing potential issues.
Another pitfall is the absence of non-regression tests when updating an existing pipeline. Failing to conduct non-regression tests when sources are updated or added can result in undetected data processing issues and inconsistencies.
Additionally, prematurely including Key Performance Indicator (KPI) calculations within dimension or fact tables, rather than defining them in user-accessible datamarts, can complicate the integration layer unnecessarily. Separating KPI calculations into user-accessible datamarts promotes maintainability and facilitates iterative updates in the future, without impacting the core integration logic. It then helps to better separate the raw integration and the analytic integration logics, leading to well defined tests.
The Ugly: trying to test everything
Searching for potential regressions throughout the integration layer can become an arduous task, particularly when the complexity and volume of data increase. Locating where merges occur and meticulously checking for regressions everywhere can be time-consuming and prone to errors. Instead, it is advisable to adopt a targeted approach, focusing on critical areas where potential issues are most likely to arise. This means your architecture clearly delineates raw integration and analytical integration.
Defining unit tests solely on data rather than functions can also lead to challenges. While data validation is important, testing the underlying functions and transformations that process the data is equally crucial. Unit tests that cover the logic behind the integration processes provide a more comprehensive assessment of the reliability and accuracy of the data pipeline.
Exposition tests – Ensuring quality data for end users
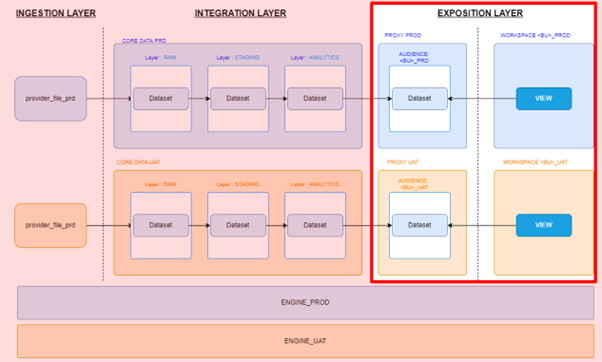
A focus on the exposition layer, where the data is finally consumed by business users
The exposition layer refers to the final stage of the data pipeline, where data is presented to end users through Business Intelligence (BI) dashboards or other user-facing interfaces. This layer focuses on making the data accessible, understandable, and actionable for users, enabling them to derive valuable insights and make informed decisions.
The Good: talking early with your end users
In order to ensure the quality and usability of the data pipeline, it is essential to define functional tests in collaboration with the intended users. These tests should be clearly documented, written down, and agreed upon beforehand. They should also include well-defined acceptance thresholds, establishing the expected behavior and accuracy of the exposed data.
Well formalized end user tests serve multiple purposes and bring several benefits to the data engineering process:
• Alignment with User Expectations: By involving end users in the test definition process, data engineers can align their efforts with the expectations and requirements of the intended audience. This ensures that the exposed data meets the specific needs and preferences of the end users, resulting in a more user-friendly and effective data solution.
• Early Issue Detection: Well-formalized end user tests act as a safeguard against potential caveats and issues that may arise during the development phase. By clearly defining the expected behavior and acceptance thresholds, any discrepancies or shortcomings can be identified and addressed early on, minimizing rework in run mode.
• Quality Assurance throughout Development: Since end user tests are well formalized, parts of these tests can be used during the development phase to validate the quality of the exposed data. By continuously checking the data against predefined acceptance criteria, data engineers can ensure that their development efforts align with the desired outcomes, resulting in higher-quality data solutions.
The Bad: getting purely technical and forgetting end users
One common mistake is neglecting to define any functional tests. This oversight can lead to a misalignment between the exposed data and the user’s needs, resulting in a subpar user experience and limited data usability.
Using UAT source data for functional tests is also problematic. While end users possess extensive knowledge about the data itself, they may not be familiar with the underlying functions and transformations performed in the data pipeline. Relying on end users to conduct tests using UAT source data can lead to inaccurate assessments and inadequate testing coverage. It’s important to distinguish between a UAT environment in a data platform and a UAT environment for source information systems. That means you should define those tests in a double run fashion, or on your unique exposition layer with an active monitoring period.
The Ugly: defining “Does everything work as expected?” tests
Defining end user tests as generic “does everything work as expected?” tests is insufficient and can lead to potential caveats being discovered later in run mode, when data engineers are already occupied with other tasks. It is crucial to define specific and detailed tests that cover the desired functionality and behavior of the exposed data.
Additionally, waiting until the data is available before defining end user tests can result in missed opportunities for early testing. By involving end users in the test definition process ahead of time, data engineers can validate and test the exposed data before delivering it to end users.
Conclusion
In the world of data engineering, implementing a TDD approach is crucial for ensuring the quality and reliability of data pipelines. Throughout this blog post, we explored the good, the bad, and the ugly aspects of TDD in data engineering, focusing on the myth of full coverage, the significance of ingestion and integration tests, and the importance of end user tests in the exposition layer.
One key takeaway is the importance of a well-defined architecture for data pipelines, specifically with a clear division between the ingestion, integration, and exposition layers. This architectural design facilitates the implementation of effective testing strategies for each layer, ensuring comprehensive coverage and validation of data at various stages of the pipeline.
Adopting a Test Driven Development framework in data engineering is essential for building robust and reliable data pipelines. By embracing the architectural division of ingestion, integration, and exposition layers and incorporating effective testing strategies at each stage, organizations can significantly improve the quality of their data solutions. Moreover, fostering open and collaborative communication between data engineers, application managers, and business stakeholders ensures that the data pipeline is designed to meet the end users’ specific needs, ultimately driving better decision-making and business outcomes.
