
The problem
Can anyone process data that comes into Apache Kafka ® ?
Kafka handles data in real-time, and even provides a set of libraries to analyze and transform data in real-time, but what about non developers, people that don’t have programming skills to develop these applications in Java or Python? Is there a way for people who do not have these skills to access the data that is relevant to them and process it in an easy way?
Answer:
If you would have asked this question some years ago, sadly the answer would be no. These people only had simple GUIs such as AKHQ (See more at: https://github.com/tchiotludo/akhq) or Kafka Tool to consult this data.
However, Confluent listened to these frustrations and requirements and developed a tool that allows everyone to process these streams of data by only using a SQL-like language, and called it KSQL.
Process Kafka data with… SQL?

Yes! Confluent KSQL is the streaming SQL engine that enables real-time data processing against Apache Kafka®. Developed at Confluent®, it provides an easy-to-use, yet powerful interactive SQL interface for stream processing on Kafka. KSQL is scalable, elastic, fault-tolerant, and supports various streaming operations, including data filtering, transformations, aggregations, joins, windowing, and sessionization.
How does it work?
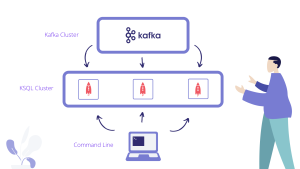
There is a KSQL server process that executes the queries against Kafka. A set of these processes can run as a cluster. If you want to add more processing power, you can just start more instances of this KSQL server. Also, these instances are fault-tolerant, so if any of them breaks down, the other instances will take over its work.Querying is simple, it’s done by using the KSQL command line that sends queries to the cluster over a REST API.
This command line is a powerful tool and allows you to inspect all the existing Kafka topics and create streams and tables and check the status of these queries (more explanation about these in the practical examples below).
If you want to know more about the details of KSQL you can get more information here: https://www.confluent.io/product/ksql/
Kafka Streams vs KSQL
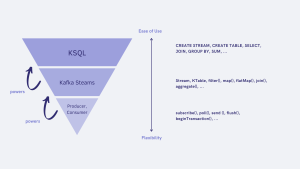
KSQL is built on top of Kafka Streams, a library that helps developers produce applications to interact with Kafka in an easier way. This library is very powerful and helpful as well but requires programming experience. To simplify the process, KSQL provides anyone who knows SQL a simpler alternative to process the data coming into Kafka.
It is important to have this in consideration, KSQL is used for people that need to quickly get data from and process it in a simple way. If more complexity is needed for processing these data streams, you’ll be better off programming your applications with Kafka Streams.
Although it does not inherit its full complexity, KSQL receives Kafka Streams elastic scalability, state management, and fault tolerance. Adding to these features, KSQL adds on top a distributed SQL engine and a REST API for queries and control.
Is Kafka and KSQL basically the same as SQL and a normal relational database?
Well, the way KSQL and Kafka work together is quite different to query a normal database. Most relational databases are used for on-demand look ups to stored and static data. KSQL doesn’t do look ups, what it does is continuous transformations of the data that comes into Kafka (stream processing). For example, imagine we have a client in a website and every click corresponds to an event send to a topic in Kafka. With KSQL we can create streams that will process that information in real time as a set of individual values. From that, we can also create tables to process those individual values to produce real time statistics.
So, what KSQL runs are continuous queries — transformations that run continuously as new data comes in — on streams of data in Kafka topics. On the other hand, queries on a relational database are one-time queries. In a relational database, the table is the core abstraction and the log is just the implementation detail. With Kafka and KSQL this is pretty much the opposite.
The tables are dependent from the log and update continuously as new data arrives in it. The central log is Kafka and KSQL is the engine that allows to create the more abstract views.
Another bakery example:
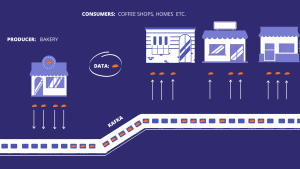
On our Kafka article we made an analogy between Kafka and a bullet train that transports bread. If you have not read that article and you are confused with the previous statement here’s the summary.
A bakery bakes bread (data) everyday (the producer) and delivers it to people’s homes or coffee shops (consumers). Before, a van made this delivery periodically (traditional messaging system). To improve its service reliability and deliver the bread as soon as possible in situations where customer demand increases, this van was replaced by a bullet train (Kafka). This train has infinite carriages (topics), that carry the bread straight out the oven to its consumers in real time.
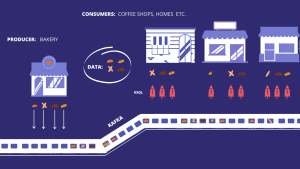
So, how does KSQL fit in this analogy? Well, we have this train that carries all this bread. Every carriage can only have one variety of bread. A coffee shop, for example might only show interest in a certain variety of bread and want that bread in slices.
KSQL can be compared as smartphone application full of different filters and options. This allows these coffee shops to order what they want and exactly how they want their bread to come in. KSQL makes it easier to filter in a simple and efficient way what they need from a large variety of bread available.
KSQL is now KsqlDB
KSQL has evolved further, and it has now been re-named ksqldb. It contains the same and even more powerful features, fixing some issues as well with the previous versions of KSQL.
ksqldb has evolved from KSQL and is now an event streaming database purpose-built to help developers create stream processing applications on top of Apache Kafka®
You can find more information at the website: https://ksqldb.io
KSQL and the current Data paradigm
With more and more people online nowadays and the large amount of data generated by their activity, it has becoming a vital process for each business to analyze and transform data into information on a real-time based.
This key process will enable business value by providing the opportunity to learn from customer activity and identifying patterns. Consequently, this will lead to an improvement of customer processes that will contribute to their satisfaction. In fact, this will enhance business processes in general by constantly monitor and adapting to any business environment. This means companies can act faster on business opportunities and avoiding threats as they occur.
To do this, traditional messaging systems that transform data periodically are not good enough for today’s standards.
With Kafka, data is stored, and processed to be used to build numerous applications for a variety of use cases in real time.
What’s more, Kafka when in partnership with KSQL allows data processing for almost everyone.
KSQL allows anyone with SQL knowledge to process any data coming into any chosen topic. This, of course without need to write any code in a programming language such as Python or Java.
With KSQL, anyone in need of data in real time in a more abstract and organized way can do it more easily. Also, as a consequent affect help their workflow and knowledge availability further.
All of this is achieved just by using a simple but powerful command line and querying away with SQL.
References
Confluent.io. 2020. [online] Available at: https://www.confluent.io/product/ksql/
Docs.ksqldb.io. 2020. KSQL Versus Ksqldb. [online] Available at: https://docs.ksqldb.io/en/latest/operate-and-deploy/ksql-vs-ksqldb/