
SEKE 2019: When and where?
Since its creation, in 1989, this is the 6th time that the conference is held outside the American continent. The last venue in Europe was Ischia, Italy, in the year of 2002. For the 2019’s edition, in Lisbon, a total of 225 papers, from 29 countries, were submitted. From those, the acceptance rate was of 39%, with a set of 140 papers to be presented in 3 days. The topics discussed fall in a variety of research areas, examples include: Software Engineering Methodologies, Software Engineering Techniques and Production Perspectives and Artificial Intelligence.
La Redoute’s participation @ SEKE 2019
La Redoute presented the paper “Collecting Data from Continuous Practices: An Infrastructure to Support Team Development” (online version available). The paper describes an infrastructure being developed by the team to collect events from Software Development Processes. This work is the continuation of a previous paper submitted and presented at the conference QUATIC 2018, in Coimbra: Improving La Redoute’s CI/CD Pipeline and DevOps Processes by Applying Machine Learning Techniques. With this new article from La Redoute, we would like to provide you a quick overview of our research.

Motivation and Research
What was the motivation underlying this research? And, why and how do we want to collect data to support development teams?
It is intrinsic in a DevOps team: we need to understand and improve our processes and products in a continuous basis. Moreover, the data being generated by software development ecosystems provides means to fulfil that need. The challenge here is to collect and to store the data, which is typically unstructured and sometimes available in fragmented data sources. Figure 1 presents a few different tools that are part of the La Redoute “DevOps” pipeline.
Internet of Events
The Internet of Events (IoE) is a term formulated by Wil M.P. van der Aalst , the father of the Process Mining discipline, to indicate all data being generated by events. Having the concept of IoE in mind, the motivation for our research is based on two main assumptions:
- Data is being generated everywhere and all the time about everything: including Software Development Processes.
- Events data support the behaviour analysis: what are the processes really being implemented by our Dev teams?
Menzies and Zimmermann write about it: “data from software projects contains useful information that can be found by data-mining algorithms”. In addition to data-mining algorithms, we plan to apply Process Mining techniques to model and capture behaviours.
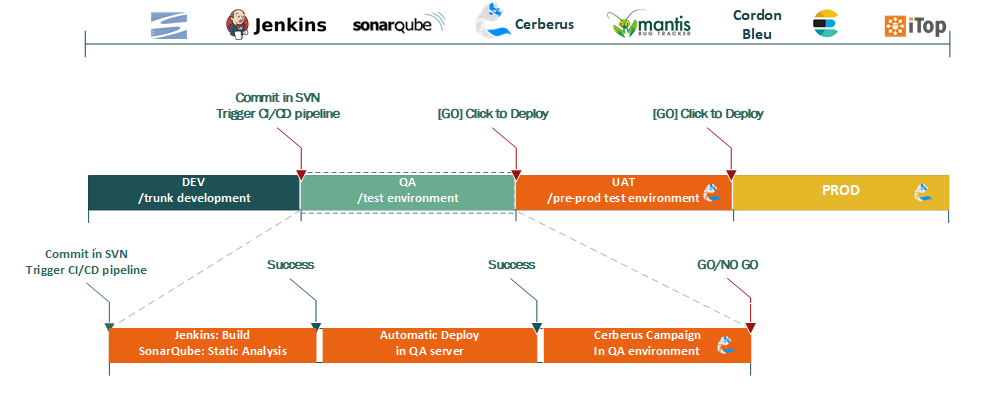
Proposed Architecture
The proposed solution is able to collect information from the continuous delivery & deployment pipeline, which includes data sources such as the source code repository (SVN), the static analysis tool (SonarQube), the continuous integration server (from Jenkins jobs) and the continuous testing tool (an in-house tool named Cerberus). Figure 2 presents a version 1.0 of the architecture. It is expected to evolve in order to enclose more events, and to improve the quality and reliability of current infrastructure. For now, it comprises two main divisions: the data extraction and the decision making process.
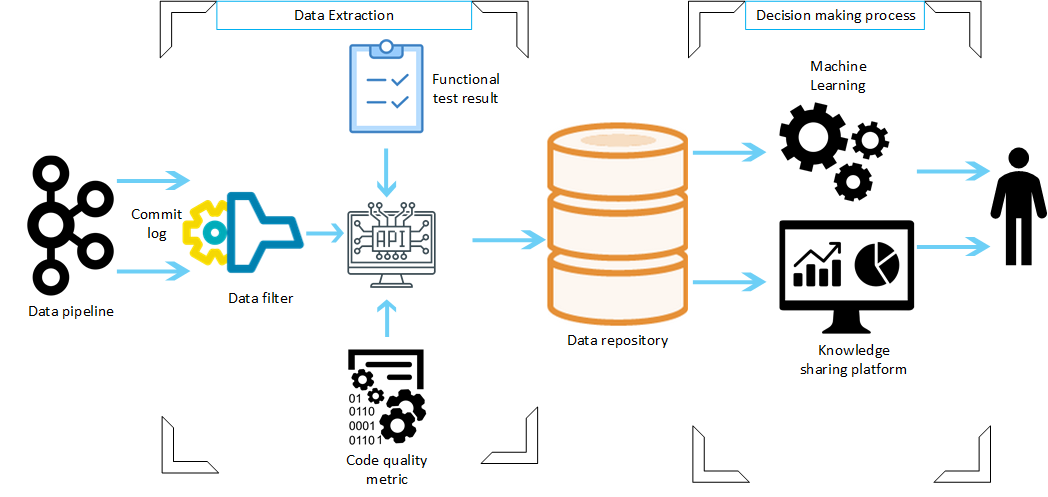
The core component of the architecture is the Data Pipeline – a Kafka cluster, deployed in a Kubernetes cluster, which for now holds the stream of Jenkins events. These events are used to gather information about SonarQube and Cerberus. Data are then stored in the Data Repository (an ElasticSearch cluster), which provides data access allowing the creation of dashboards and, in the future, allowing the application of different types of data and process mining algorithms.
What’s next?
After receiving positive and useful feedback from the researchers attending the conference, both from industry and academia, La Redoute team is more committed than ever to get insight and value from all data that is being generated inside our company. This is true not only for the business, for which we collect business events and improve the underlying processes and the customers’ experience, but it is also true for the “background” operations, such as the Software Development activities, which ultimately will have an impact on the business. With this goal in mind, we are developing a set of projects relying on Data and Process Mining techniques. Next articles will “give you the scoop” on our research.
SEKE 2020
As for SEKE 2020 conference, its installation will return to America, in Pittsburgh. It will be its 32nd edition, from July 9th to July 11th. More details are available at SEKE 2020 page.
