
E-commerce has constantly adapted to the changes imposed by the ecosystem. All players, old and new, are highly active and the circumstances of the last few years have only accelerated this process. As the business is moving faster and faster, we need to adapt our way of working to follow this trend.
As you may know, we have already moved to new software foundations for our back-office layer (Accelerate our Business with Modern Technology Foundations). It is time to tackle the front-end part to bring back more flexibility, more consistency, and most importantly more agility in our changes.
Today our frontend server is a full-stack monolith application deployed on virtual machines. It takes time to scale the platform for business events, and the infrastructure cannot be sized by functional area. We do not have the same needs for the catalog or for the checkout (unfortunately 😊)
Get to know the BFF pattern
As we started to look at how to slice and dice our monolith, it became obvious that we needed to separate the presentation layer from the data access layer and our back-office services.
The data returned to the frontend by the microservices may not be formatted or filtered according to the exact way the frontend needs to represent them. In that case, the frontend needs to have some logic of its own to re-format these data. In addition, the data can also be the aggregation of data from several microservices. Having such logic in the frontend will use up more browser resources.
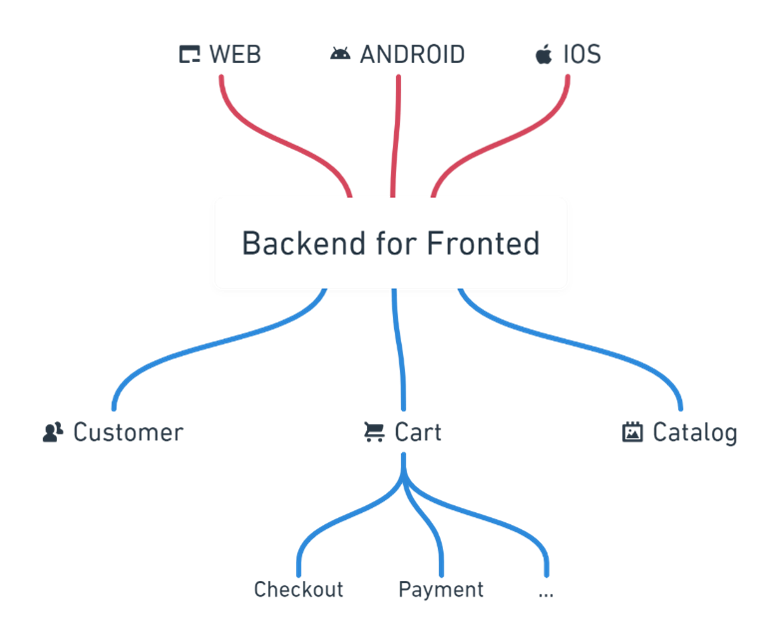
This BFF pattern (Backend for Frontend) comes with many benefits:
– Our backend services are isolated from the frontend.
– It may reduce the frontend calls and the http payload, as the BFF act as an aggregator and coordinator of request, and re-format the data for the frontends needs only.
– Faster time to market as the frontends teams can have dedicated BFF teams serving their unique needs.
– Avoid logic duplication. A single BFF should cater to a specific user experience, not a device. As we want to unify user experience between iOS, Android, or Web, in that case one BFF for all is sufficient.
Of course, every solution has its drawbacks!
As the frontend team owns his data access, it may be faster for some needs to take a shortcut and implement the service layer within the BFF. It is important to keep business logic on the right layer, avoiding mess on where this logic is owned.
Other points of attention, as the BFF is the only point of contact for the front-end, is also a single point of failure. It should be carefully considered while we design this API.
For these reasons, but also for performance reasons and in order not to be tempted to include a service layer in the BFF, we have a strong limitation to remain stateless without any database or any storage.
Ok, but…. The frontend?
Our approach to create our new front-end stack was to think about our dream and our current issues.
– How we can split Checkout, Account, Catalog, Navigation…. without inserting discrepancy across our pages.
– How we can keep our feature teams focused on their day-to-day functional domain, while guaranteeing coherence through the client navigation.
– How to inject some transversal concerns, like accessibility for example, or the primary components of our design system
If you already create some frontend stack with framework like Angular, React… you know that the main issue dealing with multiple feature teams, is to scale the development environment. The cold build time can become exceedingly long as the project grows a bit. Often, we decide to split the project, but we must manage the dependencies between the different libraries, and it could be very annoying…
Let’s not beat about the bush, we choose the Monorepos pattern, let’s explain why!
Microfrontends with monorepos
Monorepos are a hot topic for discussion. There are too many papers about why we should or should not use a monorepos pattern. Let’s explain why and how we choose this pattern for our web frontend.
We redesign our frontend application with microfrontend in mind. We will define a microfrontend as one of multiple parts of a complex application which fulfils the following criteria:
– Is composed with other microfrontends
– Is dedicated to a unique concern of the user experience
– Can be built and deployed in isolation
This will allow us to operate more smaller pieces without the overhead of operating a complex application, deploying new features at different rates for various parts of the application and providing a way for different teams to own various parts of the application.
Operating a collection of microfrontends has some disadvantages as well.
– Making a change across the entire application involves making changes to many microfrontends done by multiple teams
– Switching between teams and projects is difficult due to inconsistencies in dependencies, tooling, and standards between microfrontends
– Adding new microfrontends requires setting up a build process, testing, and deployment
– Sharing common functionality between different microfrontends requires a non-trivial solution
Monorepos on the other hand, is an architectural concept. Instead of managing multiple repositories, you keep all your isolated code parts inside one repository.

While it may seem that storing multiple projects in a single repository requires that repository to be a monolith, in case of monorepos with some tools like lerna, nx.dev… each part is in fact independent project and can be operated in isolation.
As the frontend is moving fast, monorepos is a terrific way to share some tooling across all different application packages. Style processors, npm, project bundlers, test suites, dockers, linter, prettier, CICD scripts…. We can share good practice between teams, ensure consistency between this package, and ensure concerns separation.
When microfrontends are split up into multiple repositories, making a change across the microfrontends requires a lot a synchronization between teams. This means a commit in each repository, but even worse each team needs to find time to operate this kind of application-wide changes. This is especially the case for system design changes, or accessibility. In a monorepo, it is possible to make all the changes in a single atomic commit with a dedicated team.
To help us on this pattern, we choose nx.dev as our monorepos tooling.
Nx.dev provides all the tooling for code organization and convention for code splitting, with first class support for many frontend technologies. It provides a build cache for all the components of the application that permit to scale the frontend development. Nx.dev helps us to define template for application or library with code generators, to streamline the developer’s collaboration.
Code splitting
First, we need to define how we split our frontend. Nx.dev conventions, is to split our code into apps and libraries. The app’s part will take care of the front server layer, then all the logics will be inside libraries. To be able to deploy and scale certain parts of the site independently, we have broken it down by customer request volume. Catalog and Checkout will be two separate apps. We also create some apps for internal purpose (documentation, design system …)
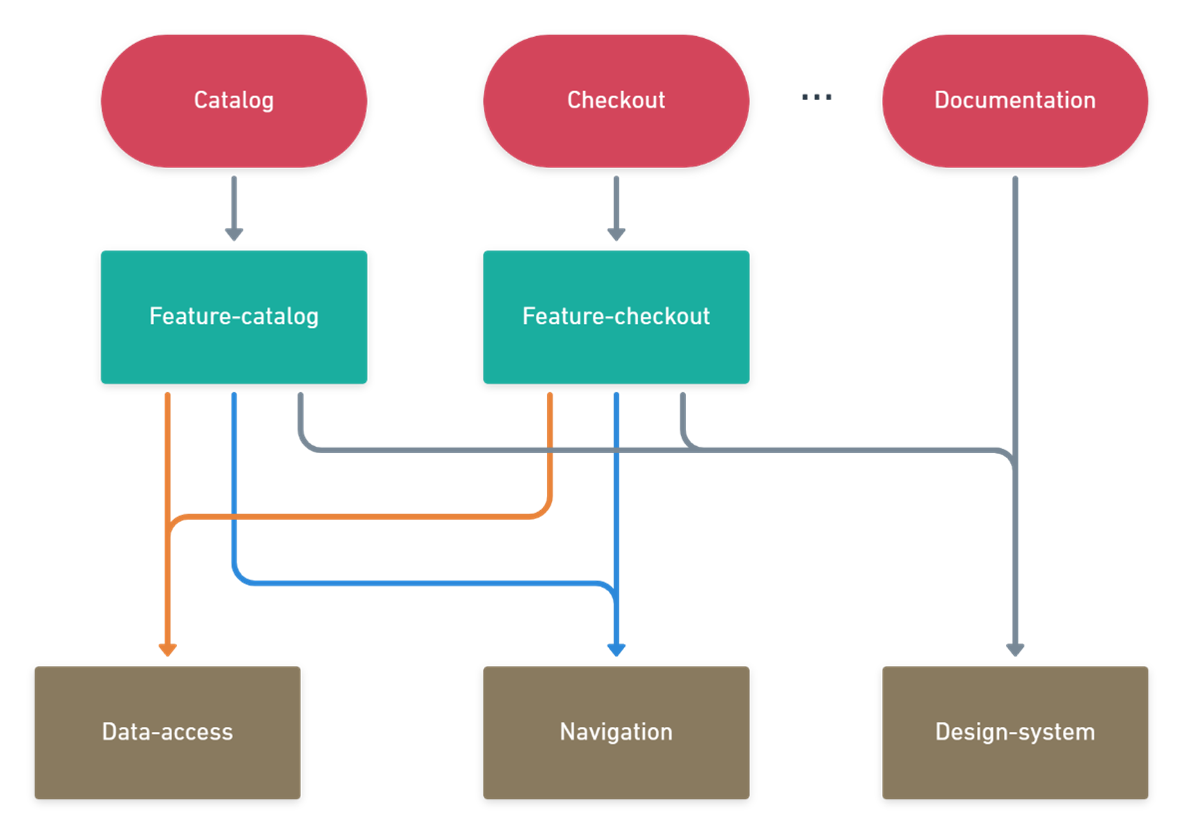
With Nx, we can partition our code into small libraries with well-defined public API. So, we can categorize our libraries based on what they contain. Features libraries contain business logic, application views, our design system contain all the presentation components, and the data-access is an auto-generated library based on the interface specification provided by the BFF.
It is crucial to establish how projects can depend on each other. Nx.dev provides a feature that can be used to enforce the graph dependencies.
Nx provides also tooling to show what part is affected by a change. We can launch automatic tests or linter, only on affected part, and we can have an automatic graphical view of this affected changes.
Developers’ collaboration
As we are several developers, located in different cities, it is hard to agree on best practice and coding conventions. Nx, help us adopting best practices by using workspace generators and workspace lint checks. Workspace lint checks with prettier is way to provide consistency on the code base. So cross-functional teams do not have nightmares about adapting to the way each team codes.
Workspace generators on their side, allow us to quickly create recurring pattern during our development (new library, new component). Generators allow us to streamline this files generation, with naming convention, tests files… We also use custom generator for the data-access library auto generation.
With multiple teams contributing to the same repository, we establish a clear code ownership with the CODEOWNERS merge request approval ‘s checks of Gitlab. Each time a change is pushed in a specific folder, and therefore, a change for a specific part of the application, approval of the team who owns this part is needed.
As an example, let’s says our design system expose a button, with a specific interface, used by two features team A and B.
We also have defined a team in charge of this design system. If the feature team A need to change the button’s interface contract, she can ask to the design system team to handle this, or she can manage this change on its own, as well as the impacts on the feature team B. When she pushes her code, via a merge request, an approval from the design system team and the feature team B will be necessary. This brings much more flexibility and interaction between the teams.
At the end, our CI/CD pipeline will take care of the developer workflow to ensure our code quality. Our CI runs the following check before automatic deployment on our staging env.
– It checks that the changed code is formatted properly.
– It runs lint checks for all the projects affected by a Merge request.
– It runs unit tests for all the projects affected by a Merge request.
We can run this task only on the affected project. This is particularly important. Monorepo-style development only works if we re-test, and re-lint only the projects that can be affected by our changes. The performance of CI checks will not degrade over time.
How it is going so far
We moved into this new stack 6 months ago. Our first surprise was to see how quickly the developers appreciate this pattern, and quickly learn the new concepts around the monorepo.
On the other hand, monorepo force us to create and maintain some tooling to handle the common task (library update, generation of data-access layer,…) or to define the common linter, test stack… Even if it was a time-consuming task at first, we are more satisfied with the gain. Our main point of attention is to define the common way of working across the different teams to find the right cursor between consistency and innovation inside each team.
Now we need to onboard more frontend teams to this new monorepo, all our teams has not made the move yet! As we will on-board more teams (personalization, marketing…), we will need to think about how we will handle dynamic and CMS contents between our front-end and the BFF. This will be our next challenge.