
Introduction
Kubernetes deployments are a key point to manage applications and tools in the cluster. We already talk of this in a previous article, for the business application. We choose to use packaged template with HELM to deploy those. But in the tests we performed, we tended to use GitOps to deploy the application with ArgoCD. But it was too many changes for the engineering teams. So as a first step, the kubernetes integration team decided to respect the dogfooding principle and use GitOps to deploy their tooling and earn some maturity on this way of working.
What is GitOps
GitOps is an operational framework that takes DevOps best practices used for application development such as version control, collaboration, compliance, and CI/CD tooling, and applies them to infrastructure automation.
The idea is to bring the Infra as Code to another level by being able to manage infrastructure directly from the code stored in git. In the K8S example, you will be able to manage your deployment in your cluster.
GitOps is used to automate the process of provisioning infrastructure. Similar to how teams use application source code, operations teams that adopt GitOps use configuration files stored as code (infrastructure as code). GitOps configuration files generates the same infrastructure environment every time it’s deployed, just as application source code generates the same application binaries every time it’s built.
With that workflow we can use developer’s best practices to manage our infrastructure, like git mechanism such as branching/tagging/Merge Requests/Versioning…
There are two ways to implement GitOps : The Pull mode, and the push mode.
In the Pull mode, it is your infrastructure that will retrieve the Git information and reconcile with it. ArgoCD and FluxCD are working in that mode. They will synchronize the Kubernetes objects with the description you created in Git.
You will describe your application with YAML, Kustomize or even HELM. And a system will synchronize the representation of your application in the cluster by installing and controlling those objects.
With that framework, the source of truth is now your code in git since its always pulled in our clusters.
In the push mode, it’s a system that push your updates in your infrastructure. For example, the GitLab pipeline that do the Helm Upgrade.
Why we choose Pull vs Push
We choose Pull mode because:
• New best pratices for Kuberentes
• We have an easier way to maintain drift between Git and K8S as its already included in most of the tools and we don’t need to develop on our side.
• Agent installed directly on the cluster, which means it is easier to deploy and maintain than gitlab runners.
• it allow us to remove gitlab runners and with that remove a lot of dependencies with the gitlab jobs.
Why we choose ArgoCD over FluxCD
During the review of the way of deployment in La Redoute. The kubernetes integration team choose to evaluate two tools, that were the most valuable at that time : ArgoCD and FluxV2.
Both are doing GitOps in Pull mode to deploy in your cluster.
Feature for ArgoCD :
• Link to git repository
• Configuration defined by Application object and registered in a project that manage the tenant (encaspuled application)
• Support YAML, Kustomize, HELM format
• Auto manage himself in the cluster (It will manage its own objects in the cluster)
• UI to see the deployments and manage it
o Object vision
o Flow vision
o Consumption in the cluster
o Remove object
o Restart deployment
o Exec in pod
• SAML to manage connection to the UI
• RBAC to manage the deployments
• REST API to consume data & perform actions (Synchronize,Rollback,…)
• CLI
Feature for Flux :
• Link to git repository
• Able to create its own bootstrap from a repository using tenants
• Support YAML, Kustomize, HELM format
• Installed in the cluster
• Image update included
• CLI
So you can get that both tools have nearly the same mechanism to work with your deployments. Its mostly the feature around them that will make us choose one or another.
And we choose ArgoCD, mostly because of the UI, and all features given by that. One of the biggest pain points given by the engineering team was that they have no real vision on what happen in the cluster (they only get the answer from the helm deploy in GitLab CI). They needed better rollback capabilities.
For now, they prepare 2 pipelines, one with the current version, and one with the new version. And it could take time to switch from one to another in case of a total pipeline launch since CI and CD are not splitted.
With argoCD we can answer both issues as well as give the developers some power in their deployments since they are not using kubectl.
And for Infrastructure tooling, we can give vision of the configuration and the state of infrastructure tools deployed in the cluster. For example, the state of Prometheus stack to the monitoring team, or Elastic stack to dev team, etc.
One last thing is that we no longer need Gitlab jobs to deploy on the cluster since the CI is separated from the CD, and the synchronization process is directly connected to the cluster. We earn some resources, but we mostly earn capabilities on the cluster from an outside tool and quickness to deploy since we don’t have to wait the job to launch.
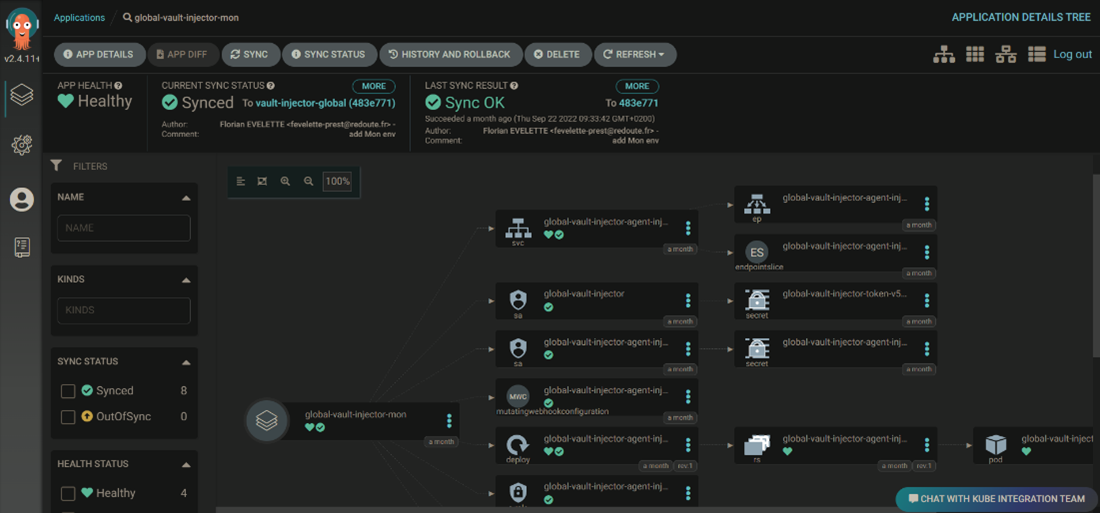
ArgoCD in La Redoute
The first step of La Redoute with ArgoCD were done for business applications. The goal was to give capabilities and vision on the deployment of their applications to the developers. But as well being able to split Continuous Integration from Continuous Delivery, is another big change, so it is still a work in progress for now. Since ArgoCD was deployed, the kubernetes integration team decided to use it to deploy the tooling of the cluster with the GitOps pattern. At that time, all charts were retrieved in a dedicated project in our gitlab and deployed thought HELM Command or kubectl apply.
To manage all the deployments of a tool we are using the ApplicationSet object. This an ArgoCD’s object that allow us to manage a set of applications. In our case we use that to gather all environments or the cluster where the application is deployed. Each environment have it’s own folder in the git repository of the application. And the ApplicationSet is used to link everything.
So, we took the opportunity to upgrade our tools by introducing the usage of kustomize as glue between the HELM Charts from the public registry and our needs of deployment.
What we implemented is the idea that ArgoCD should always use Kustomize technology to create the manisfets that will be deployed. Let’s take an example with our Prometheus deployment:
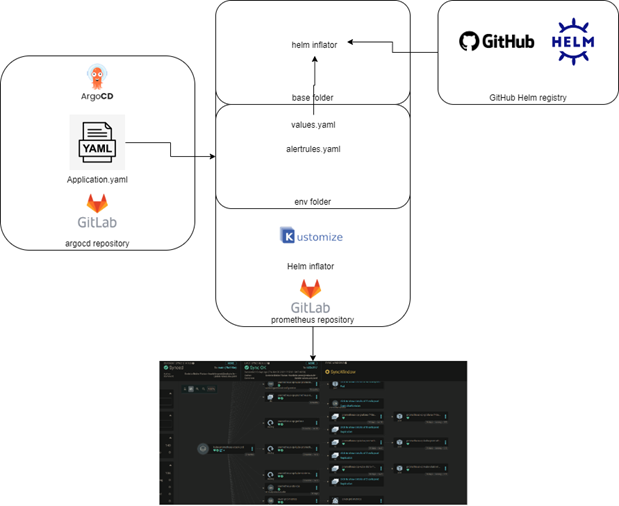
So we define the application.yaml, that is an ApplicationSet object representing the deployment for each environment we deploy Prometheus in. This ApplicationSet is linked to our Gitlab Repository of Prometheus stack. In here we have:
• The base folder: it will be the yaml that will be merged for each environment. We use in here a feature from Kustomize, Helm Inflator. This will retrieve the HELM Chart from the HELM registry provided by Prometheus
• The env folder: this will provide the specific values for your environment but as well the specific objects (for example different alerts rules following you environment).
All that merged, we can have the deployment of all our objects in the correct clusters & namespace. We can benefit from both tools HELM & Kustomize features.
This permits us to quickly follow the updates from a provider since we just change the version and deploy it in the cluster. As well as a control on each environment we manage. For example if we do an upgrade, we create a new base with the version, and plug environment by environment to propagate to production.
On the second hand, we defined clear RBAC (Role Based Access Control) for our teams. Since we are connecting with SAML we can set groups with our identity provider (Azure AD) to specific roles. For example, monitoring team have read only access for all deployments, and they can fully manage their tools like Elastic, Prometheus …
ArgoCD is providing a REST API to manage deployments or retrieve data from your deployments. We are currently working on an application that allow the neophytes to see information from the kubernetes clusters. For ArgoCD we created a page that shows the infrastructure applications and their current version of docker image and chart. The goal is to follow our tools and upgrade them when required.
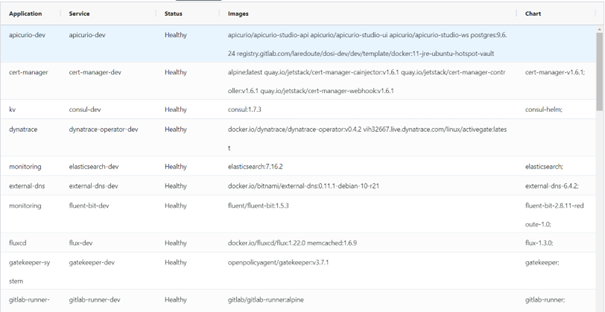
One last thing is how to monitor the deployments. ArgoCD can be plugged with Prometheus and give a set of metrics to allow us to monitor both ArgoCD and the deployments. For now we are working with the status of the application:
• Healthy : Everything is synchronized and ready
• Degraded : one object is not synchronized well or a pod is crashing
• Processing : one pod is not ready
• Missing : some object are not installed
• Out of Sync : some object are not synchronized
• Suspended : the application is blocked
• Unknown : the YAML is not well setted
We are using Degraded, Processing, and Out of sync to monitor our applications. Because for now we are not using the AutoSync feature of ArgoCD. So, if a deployment is in those states for more than 10 minutes it will trigger an alert.
It’s been now around 6 months we are working with ArgoCD, and we are very happy of the tool. We are working faster and the fact that we can show the state of the cluster quickly if really cool.
Limits
Yet there are some limitations. Since GitOps is using a lot of Git pattern. You must define clear git repositories management process and stick to it. Because if you are not following good practices, your deployments can quickly become messy, especially about following the changes on your applications. Another limitation is working with operators because they are creating object in your cluster. And if the objects are changing in team, this can cause Out of sync state even if your application is working as expected. You must set specific rules in your application set to say to ArgoCD to not check those objects. Same thing for object updated by a tool such as Kubernetes replicator. So, with that ArgoCD will just check the first creation of the object and let it live.
We had had some troubles as well using secrets, since we are working with Kubernetes Replicator. This tool is replicating secrets from one template to another secret. And by definition, it’s causing OutOfSync in the argoCD application. So, we needed to remove the check on those particular secrets.
Another problem is to comply with the current business application deployment pipeline. Right now we are doing integration test with Cerberus with a gitlab job after the deploy. When we will migrate business applications to ArgoCD we will need to prepare a post deployment hook to perform the integration tests.
Next steps
GitOps is a good framework. But as any framework it needs clear process to work with it. Kubernetes Integration team is now working on defining those. The idea is to put the AutoSync on all non-prod environment except Dev to allow change things manually to test. Production will be out of the AutoSync scope as well because we want to keep the hand when we do deployment, and we add SyncWindow to protect when we have freeze period.
Then the big step will be to use GitOps for the business applications. The idea of the first step is to keep the current workflow with Gitlab CI jobs, replace the HELM Upgrade by using the ArgoCD CLI and do a synchronization. With that, all applications will be registered in ArgoCD and the kubernetes integration team will have the ability to impact all deployments at one time. A pain point we have is to spread new things of the Central helm chart, since we need to launch all pipelines. And then do the split CI/CD with a new workflow.