Getting the events into Elasticsearch
For extracting the events from the Kafka topics, we used Logstash with the Kafka input plugin. This is easy to configure with an * for a topics pattern to read all the topics on a cluster.
As the Logstash process is just another Kafka consumer we can deploy multiple instances of it to share the workload and ensure that the topics are processed and fed into Elasticsearch in near real-time.
In addition to the Event content, we also want the Kafka metadata such as partition, offset etc to know exactly where the event came from so we use the plugin’s decorate facility to add these fields to the resulting Elasticsearch documents
mutate {
copy => { "[@metadata][kafka][topic]" => "kafka-topic" }
copy => { "[@metadata][kafka][partition]" => "kafka-partition" }
copy => { "[@metadata][kafka][offset]" => "kafka-offset" }
copy => { "[@metadata][kafka][key]" => "kafka-key" }
copy => { "[@metadata][kafka][timestamp]" => "kafka-timestamp" }
}As we are only interested in the time the events were created not ingested by Logstash we replace the Elasticsearch timestamp with the Kafka event creation timestamp
date {
match => ["[@metadata][kafka][timestamp]","UNIX_MS"]
target => "@timestamp"
}Each Kafka topic goes to its own index in Elasticsearch but we prefix the name to identify the index type and add the environment and date to the index name i.e.
index => "kafka-app-events-%{[kafka-topic]}-prod-%{+YYYY.MM}"This way we can use Kibana’s index patterns to group the indices for searching the Kafka topics by environment.
We deployed a Logstash job for each cluster (DEV, QA, UAT, STG and PROD) and all went well, ingestion was near real-time, it was lightning quick to search the events but we hit problems with Elasticsearch’s mapping.
Elasticsearch Mapping Issues
At Redoute we have many different events, from both internal applications and 3rd Party applications such as CDC, stored in JSON format. There is no guaranteed consistent field or structure usage between all these events which means that they can fall foul of Elasticsearch’s mapping.
Normally, the dynamic mapping in Elasticsearch is extremely useful in automatically mapping a document’s fields such as dates, integers, strings etc. The first time Elasticsearch encounters a new field in a document destined for an index, it determines the type and that is the type it will be for evermore.
If you try to index a document where a field has different content than when it was first encountered, such as a string instead of an integer, then Elasticsearch will either not index the entire document or drop the field from the document and index what remains.
This, it does silently so you’ve no indication that it has happened and even if you did there is no way you can get the document into Elasticsearch.
That meant that we could have a search corpus with missing events or fields. For a search engine that is completely unacceptable. Nobody will use a tool that they cannot trust!
These conflicts get worse when you use a Kibana index pattern to group and search multiple indices together. Field usage may be consistent within an index but not across all indices in the group, leading to further mapping conflicts.
We tried using an Elasticsearch mapping template to map all the fields as strings but that does not account for differing uses of JSON structures i.e., Address may be a string in one event and a multi-line structure in another.
Solution – No Mapping
The only solution that was absolutely guaranteed to create and maintain a search corpus which was a true reflection of the events in Kafka was to index all the events as simple strings.
This approach would impact the searching and aggregation functionality in Kibana but is no different to the string search facilities provided by tools such as AKHQ, only much faster.
In Logstash’s configuration this is achieved by using the appropriate Codec
codec => plain { charset => "UTF-8" }and the documents end up in Elasticsearch as
No field extraction except for the Kafka metadata.
So, in Kibana we could filter events on say topic, partition etc but not on any of the fields of the events.
This leads us to being creative but careful with our searching.
Searching for Events
Searching for strings such as customer, parcel id etc is straightforward in that all records containing that string will be returned. However, it does not guarantee that the string has the same context in all the documents returned i.e., a customer id could also be a parcel id.
So, if we are using the search to count documents, we must be careful of the results returned.
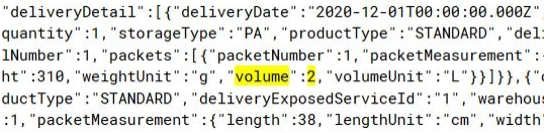
We can be a bit more sophisticated and give the search some context by using the following type of query
"\"volume\": 2"Here we escape the quotes contained in the JSON string and fortunately the search is insensitive to spaces, carriage returns etc so here we would return all documents that have a field (more exactly a portion of a string containing the word “volume” surrounded by quotes) of “volume” set to 2 (with a colon and the word “2” after it, nothing in between).
Given the “get more than you bargained for” nature of these kinds of searches against strings sometimes it is necessary to resort to filtering the results with NOT clauses.
Unfortunately, that is as far as it goes in attempting to search for a JSON structure from a string.
Where we have context contained within a JSON structure such as
"parcelMeasurement": {
"length": 36,
"lengthUnit": "cm",
…We cannot use the same technique to search for a “ parcelMeasurement” whose length is 36cm because in JSON there are no ordering guarantees.
Was it worth it?
The implementation was straightforward using off the shelf tools to give us a near real-time, fast and 100% accurate search corpus but it requires a slightly different mindset for searching which can be a challenge.
In practice it is not so difficult. The developers tend to have specific needs such as finding all the events for a specific customer, parcel etc produced from specific application(s) in a specific topic(s). Once they have created a working query, it can be saved and shared in Kibana for all to use.
Compared to the existing facilities that allow a tedious topic by topic, cluster by cluster, painfully slow sequential string searches it is a definite time saver.