
We had to accelerate our business transformation
When we decided to accelerate our Business Transformation with Kubernetes, we questioned ourselves: how will we do this?
The first answer was: We need to consider ways of getting production-ready.
Our goal is to implement Kubernetes and all support applications following the development business roadmap with all governance process up-and-running to consider ready to production.
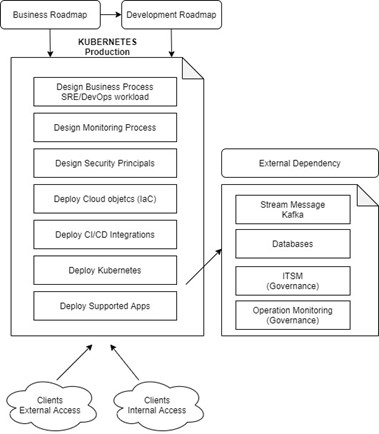
We followed a process to define the architecture and the implementation plan
In a large company, you see a lot of departments working together to support a continuous business cycle.
When you define a new target for your business (moving Kubernetes to production-ready), you need to have a view of all configuration items being affected.
To achieve successful implementation, we applied the following methodologies:
- Agile Approach Architecture (increment delivery modular components)
- Scrum Project Methodology (to be aligned with every department, change the architect or app, etc)
- ITIL for Operation Management (to implement the SRE – Site Reliability Engineer concept)
The main goal of architecting the environment is not to focus on how we will do a Kubernetes deployment, but on what we will implement in the Kubernetes environment to align with the company’s prerequisites to be ready for production.

Some issues were defined by the business strategy: what cloud to use (Google), Kubernetes as a Service (GKE), accesses to the environment with business IAM (Identity Access and Management), DNS, Routing, etc.
We defined the users and their main use-cases
The aim of the implementation of Kubernetes is to accelerate our business transformation and improve the production of the business.
With this in mind, users should be able to access Kubernetes easily without much effort.
The first step is: Who will use Kubernetes and what knowledge those users have?
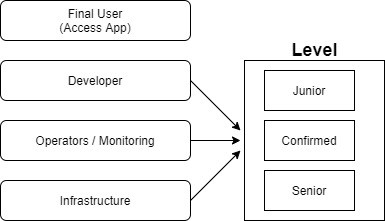
After knowing the main users that will use the Kubernetes environment, we define the process to support those users:
- Development Team: Template (helm chart for default applications), CI – continuous Integration and CD – Continuous Delivery, Tools for easy management (kubectl, kubectx kubens, etc.) and a list of articles that help use the environment
- Operation / Monitoring Team: With a step by step to help the maintainability of our environment with Recovery Actions
- Infrastructure team: With defined Terraform templates and modules to operate the infrastructure of the Kubernetes (GKE)
We defined the main architecture of a high availability environment
One of the main benefits of using Kubernetes is the ability to have high availability of your application without much effort.
On GKE we already have this HA on the infrastructure side, but when we look at the deployment of the business apps, we need to use this feature as much as we can!
First, if your application can scale, use multiple pods for it!
To avoid a single point of failure for your applications and if your application is fully scalable, use Pod anti-affinity to instruct Kubernetes NOT to co-locate Pods on the same node.
This will help you in case one of your nodes goes down or if you use a cloud provider with multiple zones in the same region and an entire zone goes down!
Then, we had to articulate our environment requirements
To define the requirement for the Kubernetes environment, we decided to implement the recommendations of the following best practice articles
Main guide on Kubernetes best Practice
Your guide Kubernetes Best Practices
Kubernetes Production Best Practices
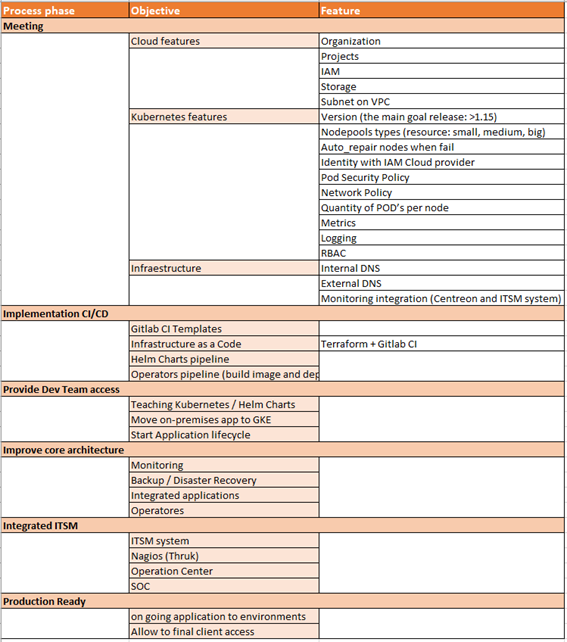
After deciding what features we will have in our environment, we start the process of implementing them.
The process took the following steps.
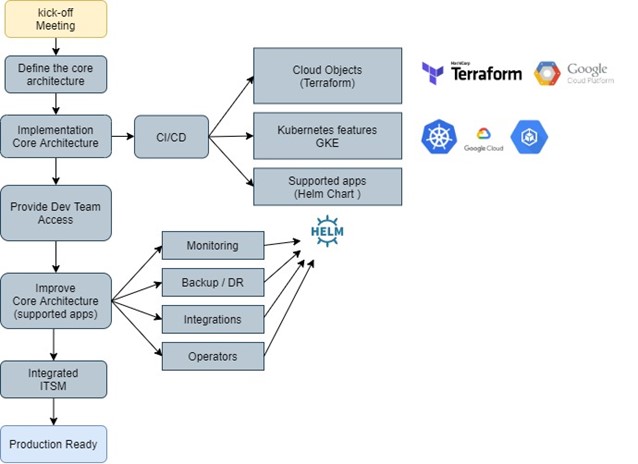
It means we started implementing cloud objects (project, VPC, subnet, IAM, etc), understanding the features we have on Google Kubernetes Engine, and the first supported applications we will deploy on Kubernetes (Vault, Consul, Prometheus, EFK, Velero, Cert Manager, etc).
To align with these expectations of implementation, the DevOps team skill and knowledge is extremely useful to achieve these goals.
Our day-by-day working progress starts with the following GitFlow process.
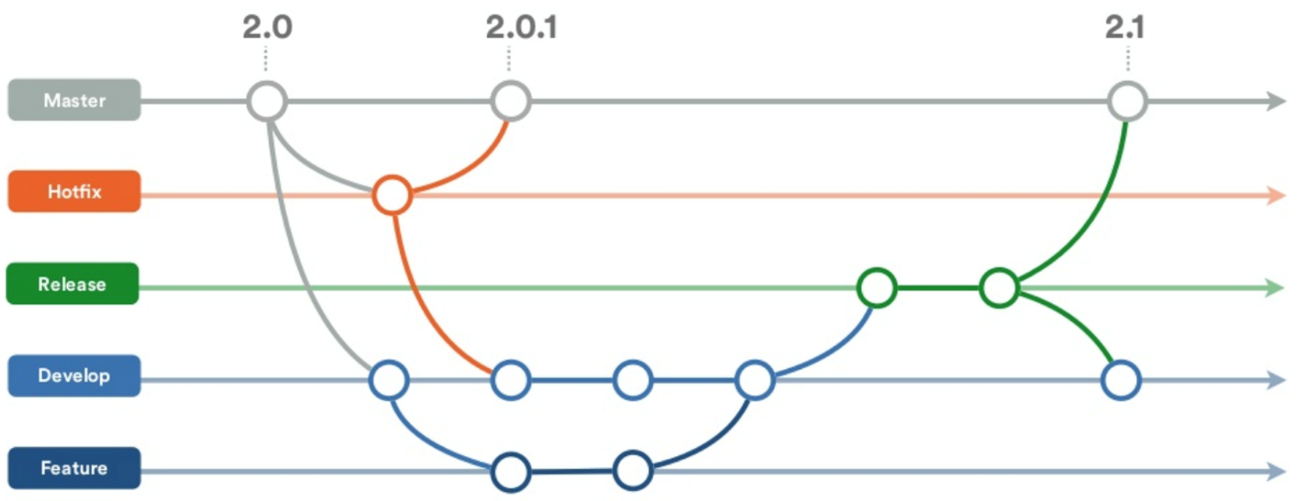
The purpose of using the GitFlow principles is to have a process to ensure that changes (for testing, development, and production) do not impact our environment. On our team we have a flow that we always use:
- Create a branch to do any changes,
- Create a merge request (we use Gitlab for our code repository),
- Merged it if everything is correct!
Reaching a successful production-ready platform requires a structured approach
Following all the steps defined for the main objective, we were able to define and implement the major good practices, together with the company’s prerequisites.
The way to success is to understand the skill level of each user in the environment in line with good agile practices. Do not hesitate, using agile and project management methodologies, keeping in mind the growth of the environment is the path to production-ready.
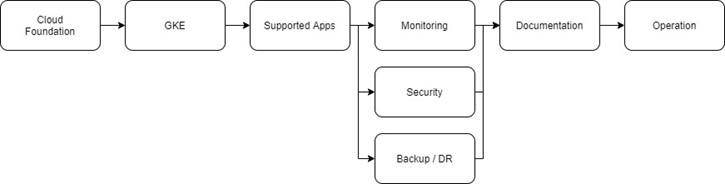
This type of implementation is to be aware that teams do not need to wait for a production-ready system to start using and studying Kubernetes.
You lead teams to use the new features at the end of the sprint.
In the following articles, we will explain technically how we implemented all the features in our container orchestration environment.